
小形克宏の「文字の海、ビットの舟」
|
|

●圧倒的な多数で否決された日本IBM代替案のアーキテクチャーとは?
榎本の話はいよいよ核心部、日本IBM代替案(以下、代替案)そのものの説明に入っていった。
「次に代替案の中身ですけれども、まず文字集合について案の中身を見てみると……向こうで説明した方がいいかな……」そう言うと、榎本は座っていたソファから立ち上がり、スクリーンの脇に移動して説明をはじめた。しかし、ここでは紙幅も限られていることだ、以降は会話体ではなく、榎本に代わって私が代替案の内容を説明することにしよう[*1]]。
[*1]……日本IBMから提供されたプレゼンテーション資料はこちら(http://internet.watch.impress.co.jp/www/column/ogata/part3_06/ibmplan.pdf)。ただし、本文では取材後に日本IBMとの間で交わされたメールによる追加説明も含んでいる。だから本文で書いたすべてが『ibmplan.pdf』に含まれてはいないことをご了承いただきたい。 まず、代替案の文字集合について説明しよう(『ibmplan.pdf』p.4/図1)。
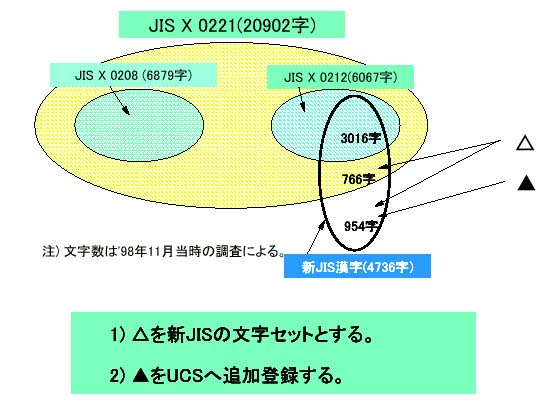
▲図1 元来JIS X 0213(以下、0213)はJIS X 0208(以下、0208)を拡張するものだ。したがって0208との併用が前提となるのだが、代替案ではこれに加えてJIS X 0212(以下、補助漢字)をも併用することが前提になっている。
次に、0213原案の半分以上を占めていた、補助漢字との重複文字を外してしまう。こうしても補助漢字が併用されているから支障はないわけだ。この重複が3,016文字だから、代替案の文字数は差し引き全1,720文字となる(以下、数字はすべてこの時点の原案にもとづき日本IBMが調査したもの。したがって制定時とは違うことに注意)。
この1,720文字の内訳だが、ISO/IEC 10646(翻訳JISはJIS X 0221。≒Unicode。以下、UCS[*2])にすでに含まれるものが766文字[*3]、含まれていないものが954文字 ある(以下、この954文字を(A)とする)。(A)については、UCS上では使用不可能なので、別途収録の申請をすることにする。
[*2]……UCSは『Universal Multiple-Octet Coded Character Set』の略で、国際的な公的規格、ISO/IEC 10646の別称。また、ISO/IEC 10646の翻訳JISがJIS X 0221だ。一方、UnicodeはUnicodeコンソーシアムが制定する私的なデファクト規格。両者は文字集合と、UCSのUCS-4以外の符号化方法は同一であり、自転車の両輪のように協力して開発を進めている。詳細については第1部第2回の本文、第3部第5回の註1を参照して欲しい。
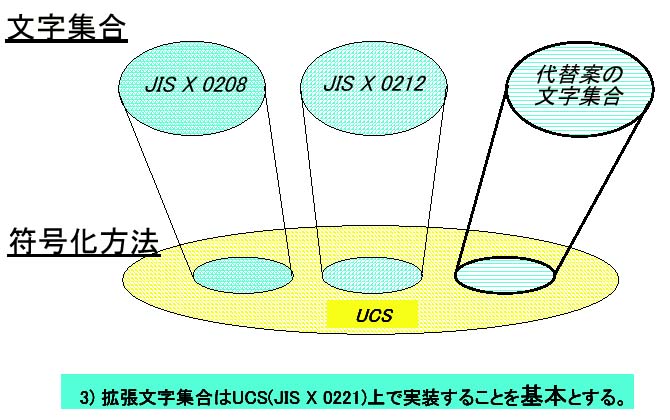
[*3]……UCSでは中国(中華人民共和国、中華民国、香港政庁、シンガポール)、大韓民国、日本、ベトナムなどの漢字を、一定のルールによって字体を統合したうえで収録している。これを『CJK統合漢字』とよぶ。CJKはそれぞれChina、Japan、Koreaの頭文字。本文にいう“0208にも補助漢字にも含まれないが、UCSには含まれている0213原案の文字”とは、つまり日本以外の国によってすでに収録されていた漢字のうち、0213原案と同じだった文字ということになる。次に符号化方法について(『ibmplan.pdf』p.5/図2)。これはUCSに定義されているものを使用する。つまりUCS-2、UCS-4、UTF-8、UTF-16のいずれかとなる。
▲図2 すでにUCSでは0208と補助漢字は収録済みなので、前述した(A)の文字を収録しさえすれば、UCSですみやかに代替案の文字を使うことが可能になる。補助漢字を併用し、符号化方法がUCS……。お気づきだろうか、つまりこれは1998年当時でいうWindows NT4.0、現在のWindows 2000の実装と結果的に同じということになる。
つまり代替案はUCS未収録の954文字さえ我慢すれば、提案時点のWindows NT4.0はもちろん、現在のWindows2000、あるいは今年後半に出るはずのWindows XPにおいても、すぐに実装が可能な案だったということになる。
最後にUCS以外の従来からの符号化方法、シフトJIS、日本語EUC、ISO-2022-JPへの対応について(『ibmplan.pdf』p.6)。ただし、これはUCSで符号化することを前提とする代替案にあって、あくまでも従来からある符号化方法との互換性をとること、つまり文字化けを最小限度にとどめて情報交換することを目的に考えられている。したがって実際の有効性は、UCSを使った場合と比べればかなり落ちる。
まずシフトJIS、日本語EUC、ISO-2022-JPといっても、さまざまなバージョンがある。ここで互換性をとる対象とするのは市場で実際に実装されている規格、つまりシフトJISはマイクロソフトが定めた『Windows標準キャラクタセット』(JIS X 0208:1997、つまり97JISではない)、日本語EUCはAJEC[*4]、ISO-2022-JPはインターネット標準のRFC1468[*5]とする。
[*4]……オープン・ソフトウェア・ファンデーション(OSF)、UNIXインターナショナル(UI)、UNIXシステム・ラボラトリーズ・パシフィック(USLP)の3者で合意された日本語EUC。『Advanced Japanese EUC』の略。規格票のドラフトはこちら(http://hp.vector.co.jp/authors/VA001240/article/euc-jp.txt)。
[*5]……JIS X 0201と0208を同時に使用するための規格。特にインターネット上で使われる。規格票はインターネット上に多く存在するが、例えばこちら(http://www.ietf.org/rfc/rfc1468.txt)。その上で、代替案では自然拡張を前提とする。つまり新しい文字を割り当てても文字化けしない完全な空き領域のみを使って拡張するわけだ。そこでそれぞれの空き領域を調べると以下のようになる。
◆ シフトJIS……1,783字(NEC特殊文字、NEC選定IBM拡張文字、IBM拡張文字、ユーザー定義外字の各領域を避けた数)
◆日本語EUC……3,680字(純粋な空き領域は664文字だが、日本語EUCは最初から補助漢字を併用するので、0213と補助漢字の重複文字3,016字を加えて3,680字)
◆ ISO-2022-JP……1,608字これを空き領域が多い順から並べなおしてみよう。
日本語EUC > シフトJIS > ISO-2022-JPつまり、ISO-2022-JPが一番少なくて1,608文字になる。そこで、このISO-2022-JPの空き領域の数に合わせて、さきに述べた代替案と補助漢字の中から1,608文字の共通文字集合をあらたに選定し、これを使用することとする(ただし日本語EUCの制限により、補助漢字と重複しない代替案独自の文字は多くても664文字まで)。その結果として従来の符号化方法と代替案の間で完全な互換性が保証され、なおかつこれら3つの符号化方法を何回経由しても、正しく符号位置を保ち続けることが可能になるわけだ[*6]。
[*6]……もっとも、前号でも引用した榎本の発表を記録した豊島文書によれば、このあたり日本IBMの話と少し食い違うようだ。以下に該当部分を再掲する。
---------------------
(前略)具体的な文字集合の選定に就ては、現行代替案の範囲とはしないが、X0212内の文字を優先する事を提案する。尚、今後、文字集合を提案するか否かは、更に検討する。
具体的には、その規模は、
Shift-JIS 空き1,783字(X0212内の文字を含む)
ISO-2022-JP 空き1,608字(一部IBM選定漢字に使うため)
EUC 空き 664字(G3補助漢字を含まず)
尚、Shift-JIS、2022-JP、EUCは、それぞれ別のサイズの文字集合となり、相互間の変換は、全てUCS経由の表引きで行なう。
---------------------
上記の豊島文書では、〈Shift-JIS、2022-JP、EUCは、それぞれ別のサイズの文字集合〉となっている。前述した通り、従来の符号化方法への対応では多くの欠点が考えられる。おそらく最大のものは、UCSで実装された代替案と、この共通文字集合を使った代替案の間で情報交換をすると、より文字数が少ない共通文字集合の方で文字化けが生じることだろう。WG2でこの代替案が審議された際、否決理由のひとつとして〈部分集合は認められない〉とされたのは、こういった事情もあると考えられる。文字化けが起こるのに部分集合を作る必要があるのか、という訳だ。
しかし、これは新しい文字を使おうとする場合に限られるし、例えば従来のシフトJISで符号化された範囲のデータが文字化けしてしまうということではない。0213附属書1のシフトJIS(Shift_JISX0213)では、既存のシフトJISデータの方が文字化けすることを考えると、この代替案で目指したものは明らかだ。
つまり、代替案では拡張する文字数よりも、従来の符号化方法との互換性の維持に重点を置いている。一方で0213は違う。WG2にとって0213の前のプロジェクトである0208第3次改訂、つまり97JISで打ち出した“空き領域は原則使用禁止”[*7]の原則のもと、たとえ圧倒的なシェアをもつメーカーの外字でも例外にせず、この領域を使って符号化している。
従来の実装との間での互換性をとるか、それともJISとしての公平な一貫性をとるか、代替案と実際の0213との違いは、詰まるところ、このような根本的な考え方の違いだと言えるだろう。
[*7]……0208規格票の解説「3.4.2 空き領域の取り扱い」を参照のこと。ここでは97JIS以前の版の0208では、空き領域を自由領域として認めていたことを批判し、空き領域を原則的に使用禁止とする考えが述べられている。
●“これからはUCSで行こう”という日本IBMの主張
さて前回、榎本はこのIBM代替案が否決された理由として、「自分の理解するところでは」と前置きして以下の3つを挙げた。
(1)補助漢字の使用を前提にしている。
(2)文字集合の一部だけを切り出すことを認めることはできない。
(3)文字コード間の変換は変換表に依存する(実装が容易な数式変換が不可能)。うち(2)については前述したが、上記を念頭に置いた上で、それではもう一度、2000年8月の日本IBM本社ビルの会議室へ戻ることにしよう。榎本の代替案のプレゼンテーションが終わって、パチンと蛍光灯がついた。私は黙って今の榎本の説明を反芻し、必死に考えをまとめている。おもむろに小田が口を開いた。
「どなたか情報部会で言っておられませんでしたっけ、0213は本来ISO/IEC 2022系なのに、シフトJISを前提に設計し過ぎたために、上位互換性をスポイルしているのではないかと」そうでしたね、と私は言った。
「電総研の戸村さんの発言ですね」0213は符号化可能な文字数の少ないシフトJISに合わせて文字数を絞ったのだが、JISはISO/IEC 2022系とUCS系のふたつから成るという大局的な立場からみれば、本来ISO/IEC 2022系である0213が、なぜ“その他”の符号化方法に合わせて文字数を削らねばならないのかという疑問も出てくる。どうせシフトJISは消えてゆくのだから無視し、ISO/IEC 2022の範囲内で必要な文字を必要なだけ収録する。その上でUCSにもそれらの収録を求めればよいではないか、という考え方だって成り立つ。小田はこういったことを踏まえているのだろう。
「私たちの案は、符号化方法はUCSを使うというあたりが元の案と一番大きく違っているんですけど、でもいつかはUCSに移行していくんですから、とにかく文字がたくさん必要だったら、そっちへ行こうよというアイデアなんですよね」なるほど、JISはISO/IEC 2022系とUCS系のふたつなのだから、その意味でも符号化方法がUCSというのは筋が通っている。つまり、これからの新しいJISの文字コードは、ISO/IEC 2022系ではなくUCS系でやろう、市場で実装されている姿にJISを合わせようというメッセージなのだ。そう考えればUnicodeコンソーシアムのオリジナルメンバーである彼等日本IBMが、ここまでUnicodeとは言わず、わざわざ“UCS”の呼称を使う理由もわかる。
「一番重要なポイントは、そこなんですね」「そう、そこなんです。そうでないと、また制約があるよというのはあまりにも悲しいですから。ただ、逆にいうと、純粋にISO/IEC 2022の系になれば、制約なく移行していくことはできる。そのあたりが、1年後に戸村さんのコメントになるんですね」
ここで小田が言う“制約”とは、もちろんシフトJISによる制約のことだ。新しい文字が使えるように拡張しようというのに、そこでまた文字数が制限されるというのは、あまりに悲しいじゃないですか、小田はそう言いたいのだ。最初からUCSで符号化すれば、そんな制限はありませんと。実は、ここには重大な“落とし穴”があると私は思うのだが、それは最後に述べる。今は小田の話を続けて聞こう。
「それにUnicode(≒UCS)で実装したら、シフトJISのような数式変換は絶対できないですからね。まあUnicode前提で考えれば、このこと自体が問題にならない。だってUnicodeはそういうものなんですから。やっぱり数式変換の方が美しいっていうこだわり、私の方からみると、こだわりですね」
つまりそれは、と私は聞く。
「“規格の美しさ”ということへのこだわりですね」
スクリーンの脇からソファに戻ってきた榎本も肯きながら答える。
「そこに、こだわりすぎてるんじゃないかなあって。Unicodeに行ったら、どうせテーブル変換(表による変換)だし」
最初からJIS X 0201とISO/IEC 2022系である0208を同時に使うことを目的に考えられたシフトJISと違い、Unicode(≒UCS)をISO/IEC 2022系に変換しようとすれば、どうしても変換表を使わなければならない。膨大なUnicodeの変換表を内蔵すれば、プログラムはそれだけメモリーを消費してしまう。しかし、それはUnicodeを実装するメリットと引き替えの、当然のハードルなのだ。
●文字の正統性より“顧客のニーズ”
もの静かな口調ながら、急に多弁になった小田は言った。
「WG2の方たちにとっては、補助漢字は調査方法が杜撰でいい加減なものだと映っていたのかもしれません。ところが私たちの案は、その補助漢字の使用を前提にしてますからね」確かに思い当たることはある。今まで会ったWG2の人々は、一様に補助漢字を一段低いものとして考えているようだった。しかし、それも故のないことではないのだ。私は自分が今まで会った人々を思い出しながら言った。
「プライドの問題なのかもしれませんね。0213を作ったWG2の委員たちは、1文字ずつ典拠を求めて資料を探し、一点一画の違いを討論しながら、同定した字体をひとつひとつ積み上げてきた訳ですよね。自分たちはそういうハードな作業をやり遂げたというプライドがあると思うんです。僕はWG2の人たちの話を聞くたびに、補助漢字は外字表を集めただけじゃないかという反感を感じるんですが、そういう作業をした人にすれば当然かもしれません。補助漢字の使用を前提にすると言えば、まずそこの問題に触れてしまうんでしょうね」うん、確かにとに小田はうなずく。
「補助漢字の約6,000文字中、およそ3,000文字は0213と同じでしたっていう言い方をすると、それはすごいプライドを傷つけるんですよ。あったりまえじゃないかと、芝野先生あたり、おっしゃったようにも聞きますけど」私は大きな声で反論する芝野委員長の姿が見えたような気がした。「あったりまえじゃないか」か……、そりゃあそう言うだろうなぁ。
「そのあたりは私どもも不安を持ってました。だけど逆にいうと、0212にある調査方法で調べたら約6,000文字ありましたと。一方で、0213で違う調べ方をしたら、補助漢字と約3,000文字重なってますと。で、この重なっている3,000文字は、ある意味で日常よく使う漢字と考えてもいいんですけど、残りの重ならなかった3,000文字だって、まだ使われる可能性のある漢字です。そうすると、すべてをサポートできるのは補助漢字しかないですね。例えば補助漢字だけにある文字も使いたいという人は出てくるかもしれないし」私はちょっとびっくりして小田の話を聞いていた。これは依って立つ論理が海と山ほど違うじゃないか。続いて榎本も言う。
「私どもから見たら、お客様たちから、あの文字を使いたい、これを使いたいって言われた際に、いえ、これはJISのなんとかという規格に入らなかったので使えないんですと言うよりも、はい、もう全部お使いいただけますよと持っていく方が意味があるんですよね。世の中では俗字とか嘘字とか言われる文字でも、ある社会で認知されて使いたいという話であれば、それはそれで一理あるなと。そこまでは行かないとしても、少なくとも補助漢字はJISで決めた文字ですからね。だから、一体なにをメーカーとしてサポートしたらいいのか、ここで考え直した方がいいなと思ったんです」多分、代替案を否決したWG2の人々が重視したのは文字の“正当性”だろう。規格票に見られる詳細な出典情報からは、とにかく間違った文字は1文字たりとも入れないという彼等の気迫を感じる。もの書きである私個人は、そのような気迫を好もしく思うのだが、しかし日本IBMの人々にとって、正当性が必ずしも一番重要なのではないようだ。彼等にとって、より関心があるのは“顧客のニーズ”なのだ。
普段そういう立場で文字を考えたことのない私は、正直言って驚きを感じたのだが、しかしよくよく考えてみれば、これはどちらが正しいと簡単に軍配をあげて済む問題ではない。大切なのは両者のバランス、相互の補完ではないか。
それにしてもと私は思う、彼らが1年でもいいからもっと早くWG2で同様の主張を展開していれば、0213は違う形になってた可能性があるのではないか。そうすれば、彼ら自身も情報部会へ要望書を出さずにすんだのではなかろうか。いや、これは今原稿を書きながらの私の独り言だ。いけない、インタビューに戻ろう。
しばらく黙っていた斎藤がここで再び口を開いた。
「情報部会への要望書(http://internet.watch.impress.co.jp/www/column/ogata/part2_10/youbousyo.pdf)で言ったのも、使う側から見ていろんなJISの文字コードがあって関係がよく分からないと。じゃあ補助漢字はダメなんですかと。だけどJISはダメだなんて言ってないんですね。ですから現状を見ると、なんか乱立しちゃってて、どれとどれを、どういうふうに使っていいかよく分からんという状況で……[*8]」
[*8]……情報部会へ彼らが提出した要望書には、以下のような文言がある。〈今回のJISの追加によって生ずる複数並列・競合規格(JIS X 0208、JIS X 0212、JIS X 0213並びにJIS X 0221など)の使い分けについての明確なガイドが工業技術院から発行されること。〉 つまり、と私は言った。
「補助漢字の再評価ということが、代替案の重要な柱としてあるわけですね」ええ、斎藤は軽く肯きながら続ける。
「別に会社として補助漢字が良いと言ってサポートしてるわけじゃないんです。ただ、補助漢字はJISとしても存在しますねと。それを無下にないものにして良いのか、その辺をきちんとケリをつけた方が良いんじゃないかっていうことです」榎本も言う。
「うちの出した代替案が、スーパーだなんて言うつもりは全然ないんです。我々は提案して否決された立場だから仕方ないんですけど、この案を見た段階で、もう少し冷静に軌道修正ができなかったのかなっていう気持ちはあるんですね」うーん、なるほど。考え込むように黙った私を見て、頃合いを見計らっていたのだろう、斎藤が言った。
「じゃあ、ちょっと休憩とりますか、5分ほど」私には日本IBMの人々に聞きたいことが、あとひとつだけ残っていた。彼ら日本IBMが0213の新しい文字をUCS(≒Unicode)の特定の場所に収録させようとした動きについてだ。インタビューはまだまだ続く。今日は長い一日になりそうだ。
●UCS未収録文字が投げかける“ナゾ”
さて、ここでいったん日本IBM本社ビルディングから時間と場所を移すことにしよう。しかし、これからも日本IBMの人々は何度も登場するはずだ。私は、これから0213の国際提案について報告しようとしているのだが、ここでも日本IBMの人々は重要な役割を演じることになる。そして、それは原案作成段階の彼らの動きや、情報部会での一連の出来事と密接なつながりがあるのだ。
ただし、その前に片づけておかねばならない問題がある。日本IBMの人々は符号化方法をUCSにしたとして、その符号位置をどうするつもりだったのだろう? 実はこれが前述した日本IBM代替案の“落とし穴”なのである。
まず、国際規格における文字の収録は、各国の提案によってされる。つまり、各国から提案がなければ収録はできない。これが大原則だ。
先に述べたように、補助漢字はすでにUCSに収録済みだ。補助漢字にも0213にもないがUCSにはある文字、当然これも収録済み。問題はいずれにも未収録の文字(代替案を発表時点の日本IBM調査で954文字)だ。
符号化方法をUCSにする代替案では、UCSで未収録である以上、それらに対して符号位置を与えることは不可能なのだ。一方、UCSの方でも提案がなければ収録は不可能だ。日本IBMの人々は、このダブルバインドをどのように解決するつもりだったのだろう?
この代替案発表の9カ月後、彼らが中心になって情報部会へ提出した前述の要望書では、0213の新しい文字がUCSへの追加が承認されるまでは、0213の原案はテクニカルレポート[*9]にとどめることが要望されている。
[*9]……テクニカルレポートについては、http://www.jisc.org/jis2.htm日本工業標準調査会『標準情報(TR)について』を参照。 代替案発表の時点から、実は0213はテクニカルレポートにして符号位置は暫定とし、正式なものはUCSの承認が下された時点で決定、と考えられていたのなら、このダブルバインドは解決できる。つまり、代替案を発表した'98年11月から、彼らは要望書の中にあるアイデアを持っていたことになる。
しかし、考えればすぐに分かることだが、れっきとした正式な規格であるJISを作ろうと集まった原案作成委員会の人々が、JISよりもグレードの落ちるテクニカルレポートにしなければ整合性がとれない案など賛成するわけがない。つまりこれが“落とし穴”というわけだ。そう考えれば提案者しか賛成しなかった事実もうなずけるのだが、日本IBMからもらった資料にも、そして代替案発表の様子を伝える豊島文書にもこれに関する記述が一切ないので、今の私には疑問を募らせる以外にない。
●彼の笑顔は、カリフォルニアの青い空
日本IBM取材の7カ月後、2001年3月3日。都下、平河町。私はある人物と1年ぶりに再会するため、おりから開催されていた『多言語情報処理シンポジウム』会場である全共連ビルに急いでいた。
樋浦秀樹。米サンマイクロシステムズの社員として、Unicodeの規格制定を受け持つUTC(Unicode Technical Committee)[*10]]に出席し、同時にアメリカ合衆国の情報技術分野に関する標準化団体『NCITS』(National Committee for Information Technology Standard)で文字コードを担当する『L2』[*11]のメンバーでもある。つまりアメリカ代表の一員としてISO/IEC 10646の審議をするISO/IEC JTC 1/SC 2/WG 2[*12]や、WG 2の下部機関でISO/IEC 10646の漢字部分の審議をするIRG(Ideographic Rapporteur Group)[*13]の国際会議に出席したりする。米国永住権保持者だが、日本国籍はまだ棄てていないという。
[*10]……http://www.unicode.org/unicode/consortium/utc.html
[*11]……http://www.ncits.org/tc_home/l2.htm
[*12]……http://anubis.dkuug.dk/JTC1/SC2/WG2/
[*13]……http://www.cse.cuhk.edu.hk/~irg/この人は、いつだって爽やかな笑顔を見せる。まるでサンマイクロシステムズのあるカリフォルニアの青い空のように。洗いざらしのジーンズにスニーカー、そして清潔なコットンのカッターシャツを合わせている。175センチは優にあるガッシリした上背で、ラフに短く切った髪の毛。年齢不詳の童顔で、育ちの良さそうな学生の多いスタンフォード大学あたりで見かけそうな外見だが、実はこの人はSolarisやJavaの国際化を進める要職にある腕利きのソフトウェアエンジニアなのだ。
私は樋浦に会ったら、ぜひ聞きたい質問があった。ビルの1階にある喫茶店に入り、再会の挨拶もそこそこに、私は聞いた。
「0213の新しい文字をめぐって、ISO/IEC 10646やUnicodeで、去年さまざまな動きがありましたよね」樋浦はグレープフルーツジュースをストローで飲みながら、じっと私の話を聞いている。
「今はもう、だいたい落ち着くところに落ち着いたっていう段階だと思います。そういう現在から振り返って、“一連の出来事”はなにをUnicodeに残したんでしょう?」いやあ、樋浦は笑いながら短く答えた。
「過去の笑い話だね」へぇー、笑い話ですか? 思わず笑う私に、樋浦はゆっくり言葉を選びながら言う。
「うん、“そういうこともあったねぇ”って感じじゃないかなあ、すでに。芝野さんの起こした問題っていうのは、確かに大きな騒ぎになった。マイクロソフトとかIBMの日本法人が芝野さん側について、いろんなことを画策したけれど、もうボートダウン(否決)されてしまった後は、彼等も含めて、全員がそれを受け止めて次のステップに向かったっていう感じに見えますね。……揺れたけれど、ちゃんと落ち着いたって感じじゃないですか?」そうか、過去の笑い話か……。結局、あの騒ぎはなんだったんだろう? 本当になにか解決がついたのだろうか。
1999年7月4日、0213の原案作成委員会の委員長であり、文字コードを管轄する国際機関ISO/IEC JTC 1/SC 2議長、芝野耕司がUnicodeコンソーシアムに宛てた一通のメールにより、国際規格にたずさわる人々を巻き込む大騒動の幕が開けられることになる。樋浦の言う“笑い話”とは、その中核をなすエピソードを指すのだろう。
私はちょうど1年前、樋浦にインタビューをした時のことを思い出していった。彼はそこで“笑い話”の詳細を話してくれたのだ。あの日も今日と同じ『多言語情報処理シンポジウム』だった。でも場所はつくば市のホテルの喫茶店。たしか空っ風の強い、やけに寒い日だった。(以下次号)
※次回より数週間お休みをいただきます。再開をお楽しみに
(2001/3/14)
[Reported by 小形克宏]