|
記事検索 |
|
|
||||||||||||||||
 |
||||||||||||||||
|
第4回:O'Reilly氏による「Web2.0とは何か」のポイント(前編)
|
||||||||||||||||
|
これまでの3回で、今のWebで起きている現象を見ていきました。今回からはそれを踏まえて、「Web2.0」という言葉の生みの親であるTim O'Reilly氏の論文「What Is Web 2.0(Web2.0とは何か 次世代ソフトウェアのデザインパターンとビジネスモデル)」に沿って説明していきたいと思います。 O'Reilly氏の挙げられたポイントに沿いながら話を進めますが、大まかなイメージを掴みやすくするため、ディテールが漏れてしまう部分もあります。原文もWeb上で公開されていますので、より詳しく知りたい方はそちらにも目を通していただければと思います。以前に読んだことはあるけど、よくわからなかったよ、という方にとっても、再トライする助けになれば幸いです。 ■Web2.0の「7つの原則」 第1回にも書いたとおり、「Web2.0」とは特定の技術やソフトウェアを指すものではありません。進化するWebの流行を切り取り、現在多くのユーザーに支持されているサービスの要素を分析して、それまでのWeb(これをWeb1.0と呼んでいます)から進化したものとして「Web2.0」と呼んでいます。 「Web2.0とは何か」は、O'Reilly氏の挙げる「7つの原則」の解説を軸に構成されています。Web1.0からの成功事例や、近年新たに登場したサービスの分析から見つけ出した主要な「Web2.0的」サービス・企業の特徴7つを「Web2.0の原則」と呼んでいます。 必ずしも、これら7つの原則を満たすことが「Web2.0的」であるために必須というわけではありません。全部を満たしていなくても「Web2.0的」な例として紹介されているものもありますし、7つを全部満たしているけれどさっぱり流行っていないサービスもあるでしょう。ひとまず、ここでは「こういうことをしているサービスは新しい=Web2.0っぽい」という程度に捉えておきましょう。
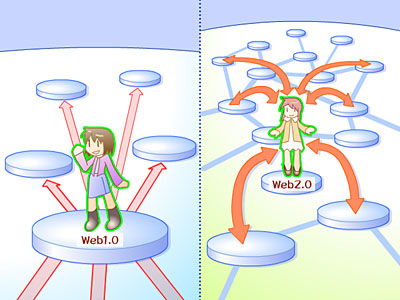
■(1)Webがプラットフォームとして振舞う 第1回の冒頭で、Webページが単なる壁新聞ではなくなり「多機能になり、さまざまなサービスを提供してくれるようになった」として振り返ったことと同じです。ただし、Web1.0の時代からWebをプラットフォームとして捉えていたサービスは存在しました。 Web1.0的なものとWeb2.0的なものの対比として、いくつかの例が挙げられています。中でも、日本で最もなじみの深い例は、NetscapeとGoogleの対比でしょう。が、Googleは知っているけどNetscapeは知らない、という方も多いと思います。現在AOLの一部門として細々とブランドを維持している「Netscape」は、1996~7年頃までナンバーワンのWebブラウザを提供するメーカーとして、多くのユーザーの支持を受けていました。しかしMicrosoft Internet Explorerとのシェア争いに敗れてしまいます。 現在のMicrosoftもまた、基本的にNetscapeと同じ形の商売をしているという点でWeb1.0的だといえます。NerscapeとGoogleのどこが決定的に違うのか? それを知るために、次の「集合知を利用する」という原則を見てみましょう。
■(2)集合知を利用する 「集合知(Collective Intelligence)」とは聞き慣れない言葉で、なにやら高尚なものであるかのような印象ですが、実際にはそんな特別なものではありません。平たく言い替えれば、次の2つです。
ひとりひとりが発信できる情報はわずかでも、まとめて加工することで、新しく価値を付け加えることが可能です。ごく単純な例でいえば、「あなたの好きなミュージシャンは?」という質問に返ってくる答えのひとつひとつを聞いても、それほどおもしろいものではないでしょう。ですが巣鴨の商店街を歩いているおばあちゃん1,000人から答えを集めて集計したら、ちょっと見てみたい気がする統計データになるでしょう。こういったことが「集合知を利用する」の一例だといえます。 先ほどのNetsaoeとGoogleの話に戻しましょう。Netscapeの指向する「プラットフォームとして振舞うWeb」は、WebブラウザなどNetscape製品に取り囲まれた環境で、Netscapeと関連企業がサービスを提供するプラットフォームでした。「集合知」との対比でいえば「Netscape発の知」オンリーで構成されたプラットフォームだといえます。 一方でGoogleは、Web全体を見渡し、第2回で紹介したようなWebというネットワークの本質を見極め、Web上にある無数のWebページひとつひとつに適切な価値をつけて、膨大な「機械によるリンク集」を作りました。 Webを、自分が生んだ情報を流すための場所としか捉えなかったのがNetscape。Web全体にある(小さな)情報を集めてそれに独自の価値をつけ、それを再びWebに流通させたのがGoogleだといえます。
両者の大きな違いは、Webの規模(利用者や公開されているWebページの総数)が増えたときに、自身の価値も一緒に増えるか、増えないかです。 たとえば今日の時点で、Netscapeが100の価値がある情報を100人のユーザーに提供していたとします。来月になってユーザーが10倍の1000人になったとしても、ひとりひとりが受け取れる価値は100で変わらないでしょう。第1回で、ユーザーが増えれば増えるほど価値の高いサービスになる「ネットワーク効果」を紹介しましたが、集合知を利用しないNetscapeのサービスには、ネットワーク効果がないのです。 一方でGoogleの場合、100のWebページをインデックスしていたGoogleが、1000のWebページをインデックスするようになったら、サービスの価値は10倍になります。「集合知を利用する」とは、Webというネットワークの本質を理解し、それを上手に利用することだ、といいかえることもできます。 そのほかに、集合知を使ったサービスの例としては、次のようなものが挙げられます。
【Amazon】 http://www.amazon.co.jp/
【ブログレンジャー】 http://ranger.labs.goo.ne.jp/
【@cosme】 http://www.cosme.net/
【はてなブックマーク】 http://b.hatena.ne.jp/ 「ブログレンジャー」、「@cosme」、「はてなブックマーク」は日本だけのサービスなので、O'Reilly氏はご存知ないようです。でも、彼がもし大の日本ツウであったなら、きっとこれらの名前も挙げてくれたでしょう(ブログレンジャーは「What Is Web2.0」の後に公開になったサービスですが)。
■(3)データは次世代の「インテル・インサイド」 なかなか意味の分かりにくい言葉です。一時期、パソコンのCMで「インテル入ってる」と連呼されていたのを覚えていますか? 説明するまでもないかもしれませんが、インテルとはPCの頭脳にあたる最重要パーツ「CPU」のトップメーカーで、「インテル入ってる」とは、「うちのPCは信頼あるインテルのCPUを搭載した、信頼できる製品ですよ」という意味のメッセージです。そして、CPUをほとんど独占して供給するインテルは、PC市場を支配する大きな力を持ったメーカーです。 Webサービスのコアになる「データ」を握っていれば、Webの世界でインテルのように支配的な立場に立てる、というのが、この原則の意味です。インテルになるためには、データを持つだけでなく、第2回で紹介した「APIの公開」をして、多くのWebサービスに自社の技術、そしてデータを提供します。 第2回で例として取り上げた「Google Maps」でいえば、APIを公開して、地図情報を「核」としたサービスが他社によって作られると、それらのサービスの存続にはGoogle Mapsが欠かせない状態になります。そうなれば、Googleが(自社にきわめて有利な条件で)地図上に広告を配信したり、何らかの利用料を徴収したりといった形でビジネスを展開することが可能になります。ただし現在、そのような動きはないので、どうなるかは分かりません。 地図データ以外に代表的な「データ」としては、Amazonの商品データが挙げられます。AmazonではAPI的の一種といえる「Amazon Web Service」のほか、アフィリエイト(Amazonアソシエイト)の形でも商品データを提供しており、Amazonのデータを元にしたレビューサイトも多数あります。 検索エンジンに集まっているWebページのインデックスや、会員制サイトの会員名簿など、さまざまな「データ」があります。それらデータの中でも、誰もが簡単に集められるものでは、独占的な立場にはなれません。収集に多額のお金や膨大な労力が必要になるとか、特殊な技術やブランド力が必要になるといった、他社にまねできないユニークな(唯一の)データを持つことが、インテルになるためには必要です。
■(4)ソフトウェア・リリースサイクルの終わり 原則4、5は技術寄りの話になります。「ソフトウェア・リリースサイクル」とは、例えばマイクロソフトが約2年ごとに「Microsoft Office XP」やら「Microsoft Office 2003」といった新バージョンを発売してきたことを指し、今後はこのような、バージョンアップのたびにユーザーに新製品を買わせるというビジネスは成立しなくなる(終わる)といいう意味になります。 Microsoft Officeのようなソフトはパッケージ(CD-ROMやDVD-ROM)で提供されており、機能がアップしたものをふたたび提供するには、新たなパッケージを作って売る必要があります。なので、あまり頻繁に新バージョンをリリースするわけにはいきませんから、ある程度改良すべきポイントを溜めて、まとめて作り直し、2年に1回ぐらいのペースでリリース、ということが行われているわけです(オンラインでの細かなアップデートはありますが)。 一方、Webサービスはパッケージではなく、ソフトウェアそのものは自社のサーバーにあって、機能をユーザーに提供します。ソフトウェアは手元にありますから、いつでも新しい機能をつけたり、改良を加えることが可能になります。 毎日効率よく改良を続けるためには、自分たち開発スタッフだけで改良するよりも、実際に利用してくれるユーザーを味方につけ、意見をもらった方がいいでしょう。また、どこまでも改良が続けられるので、いつまでもサービスは「完成」せず、進化を続けることになります。こういったことが、第1回でお話した「ベータサービスが増えた」に繋がります。
■(5)軽量なプログラミングモデル 毎日効率よく改良を続けるため、また、みんなに利用されやすいAPIを公開するためには、緻密で複雑で扱いにくいヘビーなプログラムでなく、(問題にならない範囲で)ルーズで単純で扱いやすいプログラムであることが必要だ、という話です。 大ざっぱな例でいえば、同じ「ロボットのおもちゃ」を作るなら、複雑なプラモデルよりも、子ども用のブロックのような単純な構造にしておいた方が扱いやすいよ、ということです。それほど高い技術力が要求されないので多くの人が利用できるし、多くの人に利用されるということは、それだけ(原則3の話でいば)支配的な立場に立ちやすいということでもあります。 さらに、自社のサービスやAPIをブロックのようにいろんな組み合わせを作りやすい規格(はめ込む部分の形が統一されている)にしておけば、どこかの誰かがまったく新しい組み合わせを考えて、世の中をアッといわせるようなサービスを作ってくれるかもしれません。 第3回で触れた「RSS」も、軽量なプログラミングモデルを実現するための、加工しやすいデータの一種だといえます。
■(6)単一デバイスのレベルを超えたソフトウェア Webにアクセスできるのは、PCだけではありません。PC以外の機器でも利用できるサービスを作ることで、Webの可能性をさらに広げることができます。 O'Reilly氏が、現時点での例として挙げているのがアップルの「iPod」と「iTunes」です。そのほかの例としては、携帯電話やカーナビ、先日、Webブラウザが発表されたNintendo DSなどが考えられ、また、今後も次々とWebが利用できる機器が増えていくと予想できます。
■(7)リッチなユーザー経験 「リッチコンテンツ」とか「リッチなインターネット」という言葉は、Webが登場してから何度も使わてきました。たとえば動画配信が流行ったとき、Flashが登場したときなどです。文字だけでなく動画や音声情報も加わり、豊か(リッチ)な表現力を持つコンテンツになりました、といった意味で使われます。 「What Is Web2.0」で触れている「リッチなユーザー経験」とは主に、「Google Maps」などで使われている技術として有名になった「Ajax」を指しています。Ajaxは「Asynchronous JavaScript + XML(非同期的なJavaScriptとXML)」の略称で、JavaScriptやCSSなど、以前からあった技術を組み合わせたものがベースとなっており、まったくの新しい技術ではありません。 そんなAjaxの、いちばん新しいポイントは「非同期的」なことです。従来、Web上のソフトウェアは、ユーザーが「投稿(決定、OKなど)」ボタンやリンクをクリックしたタイミングでないと、新しいデータを読んだり、何かを処理することができませんでした。そのため、クリック→通信待ち→次の画面に移る、というパターンが存在していました。 しかしAjaxでは、そういった操作に関係なくブラウザがサーバーと通信し、新しいデータを読み込み、表示することが可能になります。例えばユーザーがマウスをドラッグさせたのに対応してその先の地図データを読み込み、順次表示しているのが「Google Maps」です。 従来なら、スクロール方向の矢印をクリック→通信待ち→少し画面がスクロールした地図に切り替わる、というインターフェイスだったのが、Ajaxによってリアルタイムにスクロールする、感覚的に使いやすい快適な地図サービスが実現したわけです。 このようにAjaxを効果的に使えば、待ち時間のない、デスクトップのアプリケーションに限りなく近い感覚で利用できるサービスが作れるようになります。 さて、ひととおり「7つの原則」を見てきたところで今回は文字数が尽きました。次回は、この7つの原則をさらに読み解き、理解を深めていきたいと思います。
■URL (2006/02/27)
- ページの先頭へ-
|