|
記事検索 |
バックナンバー |
【 2009/04/09 】 |
||
| ||
【 2008/11/28 】 |
||
| ||
【 2008/11/27 】 |
||
| ||
【 2008/11/14 】 |
||
| ||
【 2008/11/13 】 |
||
| ||
【 2008/11/12 】 |
||
| ||
【 2008/11/11 】 |
||
| ||
【 2008/10/31 】 |
||
| ||
【 2008/10/30 】 |
||
| ||
【 2008/10/29 】 |
||
| ||
【 2008/10/28 】 |
||
| ||
【 2008/10/27 】 |
||
|
|
|
||||||||||||||||||||||||||||
| “情報化時代”に追いつけるか? 審議が進む「新常用漢字表(仮)」 |
||||||||||||||||||||||||||||
|
第2部 新常用漢字表と文字コード規格 |
||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||
|
JIS X 0213が制定された2001年と現在を分けている大きな状況の変化、それはUCS(=JIS X 0221=ISO/IEC 10646≒Unicode)を審議する国際機関WG2で、互換漢字に対する風当たりがより強くなってきていることだ。 将来もしも常用漢字に追加される漢字が新字体だった場合、前回書いたような漢字政策の玉突き現象によって、JIS X 0213で包摂分離せざるを得なくなる文字がある。この場合、分離前と分離後の字体の違いはわずかなものだ。したがってこれをUCSに新しい文字として提案する際は互換漢字になると思われる。ところが最近では、WG2において互換漢字はなるべく認めないようにしようという空気が強くなってきている。だからその審議には強い抵抗があることが予想される。 ● UCSと往復の保全性 そもそもこの互換漢字とはいったい何なのだろう。もともとUCSは、多国間で使用可能な国際文字コード規格としては後発に属する[*1]。つまりUCSの制定前から、すでに各国には文字コード規格が存在しており、これを多国間で使用可能にする枠組みも存在していた。そうした中でUCSを普及させていくには、旧来からある規格との間の互換性を保証する必要があった。UCSを使う最大のメリットは、従来は考えられなかったほど膨大な数の文字が使用可能になったということなのだが、それだけでは今ほどUCSは普及しなかっただろう。新しい規格の普及を進める上で従来の規格と互換がとれていることは、とても重要な条件なのである。その解決法として考案されたのが互換用文字(compatibility character)であり、その中でも漢字のことを「CJK互換漢字」(以下、互換漢字)と呼ぶ。一般に文字コード規格同士で互換性があるとは、単に符号の対応がとれているだけでなく、往復の情報交換をしても符号が変わらない(文字化けしない)ことが求められる。つまりA→Bだけでなく、A→B→Aできちんと元の符号に戻るということだ。これを「往復の保全性」(round trip integrity)と呼ぶ。前回の終わりで少し触れたように、JIS X 0213は制定当時に人名用漢字許容字体として運用されていた常用漢字の異体字を新たに収録したが、このうち「祝」の異体字を例に説明しよう。
JIS X 0213ではネ偏の「祝」を面区点1-29-43に、示偏の「祝」を面区点1-89-27に収録している。一方でUCSではネ偏と示偏の「祝」をU+795Dに統合している。そこでJIS X 0213とUCSの間で往復の情報交換をするとどうなるか。両者は対応がとれているから、JIS X 0213の符号はいったんUCSに変換できる。ところがこれを再度JIS X 0213に戻すと、最初は面区点1-89-27の示偏「祝」だった符号はネ偏の「祝」の面区点1-29-43に文字化けしてしまう。このように単に対応がとれているだけでは完全な互換性は保証できない。一対一対応になっている必要がある。このケースで言えば新規に示偏の「祝」をUCSに収録すれば問題は解決する。 ところがここで示偏の「祝」を収録すれば、よく似た字が規格に含まれてしまい規格の整合がとれなくなる。同じ文字に違う符号を与えてしまうことを重複符号化と言うが、これと同じことが起きてしまうのだ。そこで特別に互換用文字/互換漢字という枠を設け、使用を制限した上で収録することにした。このケースでは示偏の「祝」をCJK互換漢字領域のU+FA51に収録している。 その制限とは、互換用文字は自国の国内規格との互換目的だけにしか使えないことだ[*2]。この場合では、互換漢字である示偏の「祝」を使うことができるのは、UCSの符号化方法によりJIS X 0213の文字集合を実装したり、UCSとJIS X 0213との間で情報交換をしたりといった目的に限定されている。つまり、日本以外の中国や台湾のメーカーが自国の漢字としてこれを使うことはできない[*3]。このように制限しなければ後述する統合漢字と混同してしまい、規格としての整合がとれなくなる。 ● 複数の規格を1つの符号位置に統合するCJK統合漢字 ここで大事なことは、UCSの中で互換用文字はあくまで例外的な存在であることだ。例えばUCSの和訳版であるJIS X 0221は互換漢字について、規格本文で次のように注意を促している。
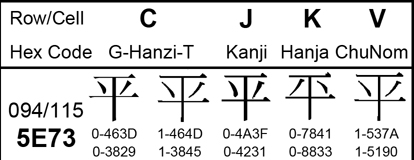
もともと国際文字コード規格であるUCSにおいては、文字集合全体を参加各国が共有し、他国が提案した文字でも自由に使ってよい(実装してよい)という考えが基本にある。これが最も明確に現れているのがCJK統合漢字(以下、統合漢字)だ。CJKはそれぞれ中国(China)、日本(Japan)、韓国(Korea)の頭文字。最近ではこれにベトナム(Vietnam)が加わりCJKVとも呼ばれる。実際にこの統合漢字がUCSの規格票でどのように表示されているか見てみよう(図2)。
U+5E73という符号位置に5つの「平」が併記されている。上部に太字でC、J、K、Vとある。このうちCはさらにGとTの2つに分かれてるが、Gは中国、Tは台湾だ[*4]。これら5つの区分の下に「平」の字が置かれているのがわかる。注目してほしいのはその下にある数字で、これは各国の国内規格の符号位置だ。つまりそれぞれの「平」は典拠(UCSではこれを原規格と呼ぶ)である各国の規格にある例示字体なのだ[*5]。 ● 統合漢字と互換漢字の違い ここからわかるように、統合漢字とは各国の国内規格を1つの符号位置に統合したものだ。Webなどを検索すると、よく統合漢字が統合しているのは言語であると説明されているようだ。それが間違いとまで言わないが、正確には各国の文字コード規格を統合したものだ。ではこれが何を意味するのだろう。例えば出版社の平凡社が自社名を表記する際、JIS X 0208に例示されている2、3画目を「ソ」の形につくる「平」とは違う、「ハの平」を使うことはよく知られている。これは書店に行けばすぐに目にすることができるほど馴染みのある字体といえる(写真1)。
そこで仮にこの「ハの平」が何かの理由でJIS文字コードに収録され、これを日本が統合漢字の領域に提案したとして、UCSでは採用されるだろうか? 残念ながら無理だ。どうしても必要なら前述の互換漢字として提案するしかない。なぜなら図2のK欄を見るとわかるように、すでにU+5E73の統合の範囲(包摂の範囲と同じ)に「ハの平」が含まれているからだ。 この例からわかるとおり、たとえ他国の規格の字体であっても、統合の範囲に含まれていれば日本は新規収録を提案できない。つまりUCSを使う限り日本は韓国の規格を無視することはできない[*6]。同様に中国・台湾・韓国などの国も日本の規格を尊重しなければならない。このようにしてUCS参加各国は統合漢字を共有している。だからこそ、他国が提案した文字であっても自由に使ってよい。例えば日本で人名によく使われる「ハシゴ高」はJIS文字コードには収録されていないが、Windows VistaやMac OS Xでは台湾の規格CNS 11643-1992からUCSに収録されたU+9AD9として実装されている[*7]。 同時に見逃してならないのは、漢字規格を1つに統合することにより東アジア各国の規格との互換性も保証できたということだ[*8]。前述の往復の保全性と同様、互換性という意味からも統合漢字は後発の規格であるUCSにとって必要だったと言える[*9]。 もともと統合漢字にとどまらず、UCSに収録された文字は審議に参加する全部の国の共有物だ。これに対して互換用文字は自国の国内規格と互換をとるためにしか使えない。つまりUCSの原理からは例外的存在だ。互換用文字の中でも互換漢字はさらに面倒な性質を持つ。表語文字である漢字(語を字で表す)は、ラテン文字など表音文字(字で語を表す)と比べると全体の文字数が多くなる。互換漢字は対応する統合漢字と細かな違いしかないから互換漢字としてしか収録できなかったわけで、そのように細かな違いを区別し始めれば、あっという間に外見がそっくりの互換漢字がUCSにあふれ、他の文字が収録されるべき領域を圧迫するに違いない。その意味でも互換漢字はUCSにとって「厄介者」なのである。 ではWG2におけるこうした互換漢字への見方が、具体的に審議の中でどのような形で現れているのか、次回はその実例を見てみよう。
2008/07/28 14:25
- ページの先頭へ-
|