|
記事検索 |
バックナンバー |
【 2009/04/09 】 |
||
| ||
【 2008/11/28 】 |
||
| ||
【 2008/11/27 】 |
||
| ||
【 2008/11/14 】 |
||
| ||
【 2008/11/13 】 |
||
| ||
【 2008/11/12 】 |
||
| ||
【 2008/11/11 】 |
||
| ||
【 2008/10/31 】 |
||
| ||
【 2008/10/30 】 |
||
| ||
【 2008/10/29 】 |
||
| ||
【 2008/10/28 】 |
||
| ||
【 2008/10/27 】 |
||
|
|
|
||||||||||||||||||||||||||
| “情報化時代”に追いつけるか? 審議が進む「新常用漢字表(仮)」 |
||||||||||||||||||||||||||
|
第2部 新常用漢字表と文字コード規格 |
||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||
|
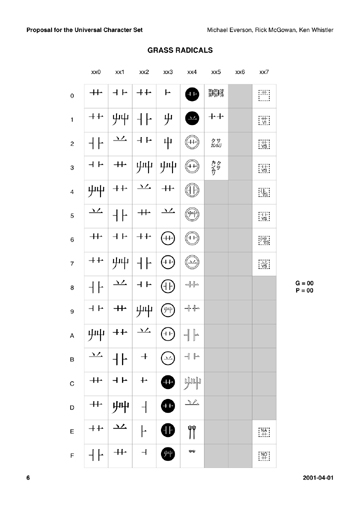
● 7年前の4月1日に出されたある提案 前回は互換漢字というものがUCSの中では例外的な存在であり、非漢字圏の国々から厄介者扱いをされていることを述べた。今回はまずその実例を見るところから始めよう。少し前になるが2001年4月1日、WG2にアメリカ代表団が提出した文書番号n2326『Proposal to encode additional grass radicals in the UCS』(草冠をUCSに追加して符号化する提案)という書類だ(図1)[*1]。これは新しい文字をUCSに追加する正式な提案書だ。
見てわかるとおり、草冠のさまざまなバリエーションが、じつに94文字も提案されている。よく見ると左上からxx00~xx05の6文字が、全く同じ形でxx35まで繰り返し提案されている。さらに丸付きの草冠、そして二重丸付き草冠、果ては「クサカンムリ」という組文字まである(しかも縦組と横組の2種類)。もしこれが本当に承認されたら、外見がそっくりな草冠が大量に重複符号化されUCSは大混乱になるに違いない。漢字を使わないはずのアメリカが、一体何を考えてこんな提案をしたのだろう? じつはこの提案書、日付が示す通りよくできたエイプリルフールなのだ。前述のように、日本はJIS X 0213の新しい文字をWG2に提案中だった。これらの中には、UCSの規準から言うと既収録の文字と同じ字であり、本来は提案が却下されるようなものが多く含まれていた。 例えばJIS X 0213では2面85区84点~2面85区87点として全部で4種類の草冠を新規収録している(図2)。このうち2面85区86点と2面85区87点は、すでにUCSに収録されているU+8279とU+4491と対応するが、2面85区84点と2面85区85点がUCSにはない。しかしU+8279との違いはわずかだから、日本はこれら2文字を互換漢字として新たに提案していた。そうした日本に対する非漢字圏諸国の反応を形にしたのが、この『n2326』なのだ。「そんなに草冠が必要と言うなら、我々がこれだけ提案しても文句はあるまい?」というところだろうか[*2]。
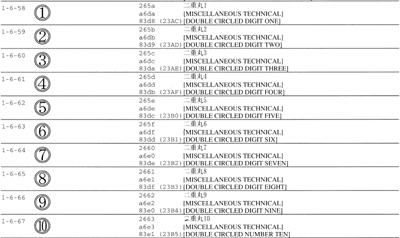
これは感心するほど細部までよく考えられていて、例えばxx42~xx47の二重丸付き草冠などは、明らかに当時同じく日本が提案していたJIS X 0213の1面6区58点~67点の二重丸付き数字(図3)への当てつけであり(なんで以前からある丸付き数字U+2460~では足りない? という呟きが聞こえそうだ)、隅から隅まで味わい深い文書なのだが、やはり最も注目すべきはこれら草冠が互換用文字として提案されていることだろう[*4]。つまりエイプリルフールに隠された彼等のメッセージは、自分達しか使えない互換漢字を大量に提案してきた日本の姿勢に対する反発だったと考えられるのである。
● 互換漢字の収録に強く反対するアメリカの意見 このように2001年当時から互換漢字はいささか波紋を投げかける存在だった。そしてこのころはジョークで済んでいたものが、現在では真剣な議論のテーマになりつつある。例えば2008年3月20日の文書番号n3409『AMD5 ballot results』のうち、イギリス代表団(P.10)とアメリカ代表団(P.12)の文章を読んでほしい[*5]。この文書はWG2の上部機関、SC2で行われたISO/IEC 10646の追補5(AMD5)に対する各国の投票結果をまとめたものなのだ。このとき日本は、放送関係の業界団体である電波産業会(ARIB)が制定したデータ放送用規格にある漢字6文字を、互換漢字として提案していた[*6]。これに対してアメリカとイギリスは明確に反対し、互換漢字として追加するのでなく既にあるバリエーション・シーケンスを使って符号化すべきとする立場が明らかにされている。ここではアメリカ代表団のコメントを翻訳の上で引用しよう。日本が提案した「恵」の互換漢字を「恵A」、これに対応する既収録の統合漢字を「恵B」とする。具体的な形状は図4を見てほしい。
「バリエーション・シーケンス」「正規化」については追って順々に説明しよう。ひとまずここでは、アメリカが今までのような互換漢字の追加には問題があると指摘していること、そしてこれに対する解決法が新たに登場し、彼等はこれを強く支持していることを覚えておいてほしい。 しかし、次のような意見が出るかもしれない。これはWG2の内部事情に過ぎないではないか。そもそも漢字を使わない国々にとって、しょせんは互換漢字など対岸の火事なのだ。そのような漢字に無知な国々が多数を占める場所で反対の声が高まっていると言って、なぜ我が国の国語施策の中心である常用漢字表の改定まで影響されなければならないのか? 確かにそうだ。それに前述したJIS X 0213の互換漢字では、結局は日本の提案は承認されている。また、上に述べたデータ放送用の互換漢字も、結局は賛成多数で可決されている[*7]。だから将来の常用漢字表が改定により、互換漢字をUCSに追加提案しなくてはならなくなったとしても、日本代表団が多少苦労はするだろうし時間もかかるだろうが、最後には承認されるのかもしれない。 ところが無事に規格に収録されたとしても実装の問題が残る。WG2で米英が互換漢字に反対するのも理由がある。具体的には互換漢字は別の字体に置き換わってしまったり、特定の場面に使用を禁止されていたりする。この問題は将来起こるのではなく、現在すでに起こっている問題だ。個人的には政令に根拠を持つ文字を互換漢字に頼るのはそろそろ限界が来ており、新しい枠組みを考えた方がよい頃合いが来ているように思う。次回はそのあたりを考えてみよう。
2008/07/29 13:20
- ページの先頭へ-
|