|
記事検索 |
|
|
||||||||||||||||||||
特別編24 JIS X 0213の改正は、文字コードにどんな未来をもたらすか(7) 番外編:改正JIS X 0213とUnicodeの等価属性/正規化について(上) |
||||||||||||||||||||
|
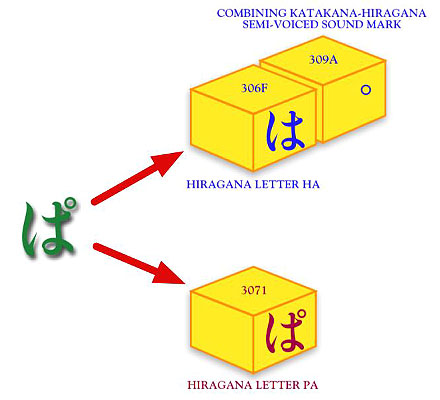
■Unicodeの正規化と改正JIS X 0213の関係 今回はMac OS Xにおける改正JIS X 0213の実装を分析する予定だった。しかしこれを変更し、番外編として2回に分けUnicodeの等価属性/正規化と改正JIS X 0213についてお伝えしたいと思う。Mac OS Xについても並行して書いているので、そんなに遅れないで公開できるはずだ。どうかご了解ください。 等価属性/正規化のどこが改正JIS X 0213と関係あるのだろう? それは、これにより改正JIS X 0213のうちで、UnicodeのCJK互換漢字と対応付けられた文字が、期待通りに使えない可能性が出てしまうからなのだ。では、この等価属性とか正規化とは何者か。 私は今までこの連載で、文字セットと符号化方法を共有する2つの規格、UnicodeとUCS(ISO/IEC 10646=JIS X 0221)の関係を「=」ではなく「≒」と表現してきた。文字コード規格にとってほとんど全てとも思える2つを共有するくせに、なぜ「=」で結べないのかというと、Unicodeには具体的に実装をするため必要な周辺規格や、収録された文字体系についての解説などが豊富に揃えられているからだ。 ここに公正中立を旨とする国際機関が策定したUCSと、Unicodeとの性格の違いが端的に表われている。Unicodeにとって実装できない規格は意味がない。こうした要請によって整備された多くの周辺規格の1つが正規化だ(UCSでは、正規化をUnicodeの周辺規格を引用する形で規定している)[訂正1]。 ■たくさんの文字を収録するが故の、Unicodeの悩み 世界中の文字を符号化しようというUnicodeの中には、文字の外見が同じに見える符号がたくさんある。例えば半濁点付きの平仮名や片仮名がそうで、以下のように違う符号を並べると、少なくとも外見だけでは見分けがつかない。 ■図1 事前合成形の「3071」でも、結合文字を使って合成した「306F+309A」でも、同じ「ぱ」だ
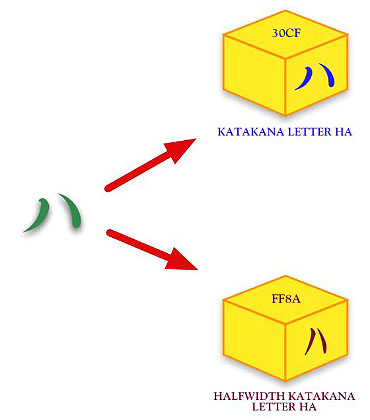
これは独仏伊西などの各国で使われているアクセント記号付きラテン文字でも事情は同じだ。本来こうした「同じ」文字[*1]を複数収録することを、文字コードの世界では「重複符号化」と言い、タブーとしている。一対多対応になるような曖昧な符号化を許してしまえば、安定した情報交換ができなくなり、規格への信頼が崩壊するからだ。 問題が起こるのは情報交換だけではない。画面に表示される文字の形は同じように見えても、それを表す符号がバラバラに1つのシステムの中で存在すれば、ソートや検索、あるいはOSがファイル管理をする際に不都合が生じてしまうことになる。 こうした曖昧さをなくすには、どうすればよいのだろう? それを説明する前に、Unicodeにおける別の重複符号化の例を見てもらおう。昔から日本のパソコンユーザーを悩ませてきた半角カタカナのケースだ。 ■互換用文字と「同じ」文字 日本において支配的なパソコン向け符号化方法であったシフトJISは、アメリカ英語を符号化するASCII(ISO/IEC 646)の上位互換を目指したJIS X 0201と、漢字を符号化するJIS X 0208を、同時に扱えることを最大のメリットとしていた。これによりプログラマは面倒な手続き[*2]なしに日本語プログラムを作れるようになった。 しかし、シフトJISはこのメリットゆえに、JIS X 0201とJIS X 0208の重複部分(カタカナ、英数字、いくつかの記号)を書き分けるため2通りの符号位置を持つというデメリットも抱え込むことになった。これらは便宜的に「全角」「半角」と呼び分けられているが、同じ文字が2つの符号位置を持つ重複符号化に変わりはない。 シフトJISをUnicodeに変換しようとする際、「半角」の英数字と記号については簡単だ。Unicodeが絶対的と言ってよいくらい互換性に注意を払うASCIIの収録文字に対応させればいい。「全角」のカタカナと句読記号も、JIS X 0208を原規格として収録されたレパートリに対応させるのが真っ当だろう。 問題なのはこれらに対応する片割れ――「全角」の英数字と記号、「半角」のカタカナと句読記号だ。Unicodeがこれらを丸呑みしてしまえば、そのまま重複符号化の危険が発生することになる。しかし、シフトJISが日本で支配的な地位にある以上、Unicodeはいくら問題が多くてもこれと互換性を確保しなければならない。これは後発規格の宿命だ。 結論から言うと、Unicodeではこの半角カタカナも収録されており、図2のように「ハ」と「同じ」ような文字が2つある。 ■図2 Unicodeには「ハ」と同じに見えるような文字が2つある
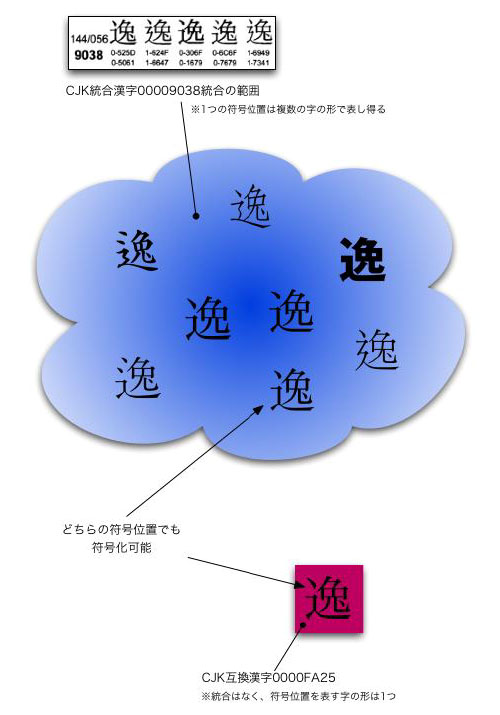
上図の「30CF」と「FF8A」同士は、図1のように外見の区別が付かないほど「同じ」ではない。しかし両方とも「ハ」と読める。図のうち下の方が、あの見慣れた「半角」のカタカナだ。Unicodeは、互換性を確保するためだけに使われる「互換用文字」(Compatibility Character)という属性を与えた上でこれを収録し、シフトJIS等、日本ローカルの文字コード規格との情報交換以外には使ってはいけないことにした。 ただし、いくら使用を制限したとしても、図1の場合と同様、1つのシステムの中でこれらが混在すれば、さまざまな不都合が生じる現実に変わりはない。我々のように「半角」「全角」が混在するシフトJISのデータを蓄えているユーザーこそ、この重複符号化の問題が切実であるはずだ。さて、Unicodeはこの問題をどのようにして解決したのだろう? 種明かしの前にもう1つだけ重複符号化の例を見てほしい。CJK互換漢字(以下、互換漢字)だ。以前、特別編22で互換漢字の説明のために使った図を再掲する。 ■図3 互換漢字と、それに対応する統合漢字の関係
図の下の方に「どちらの符号位置でも符号化可能」とあるのに注意。「逸」という統合漢字「9038」には、さまざまな文字の形が統合されており、ここには「FA25」の互換漢字の形も含まれている。実際のところ、UCS規格票「9038」のC-G欄の形(図3の上に4つ並んでいるうちの左端、台湾のもの)と、「FA25」の形(下の赤い四角の中の形)はまったく「同じ」ように見える。つまり、ここでも重複符号化が発生しているわけだ。 ■2つの等価属性 こうした問題の解決のためには、紛らわしい文字を一切収録しないのが一番だ。しかしそれは、気高くはあっても現実からは遊離している。そこでUnicodeは、こうした文字をそのまま呑みこむかわりに、符号同士の「関係」をきちんと定め、その運用ルールを規定することにした。 まず、どちらが正しいとすることはせず、互いに「同じ」と見なす(=同一視)。これが「等価」(Equivalance)であり、Unicodeを理解する上で重要なキーワードとなっている[*3]。 そして目的に応じた処理が可能になるよう、この等価にもとづく属性を2種類定めた。図1のような場合を「正規等価」(Canonical Equivalance)と呼び、本質的な意味で互いを区別できない符号とする。ここまでの私の説明では、わかりやすくするために「見た目」から入ったが、それだけが問題なのではなく、何もかも「本質的に同じ」符号なのだ。 これに指定されているのは、図1のように事前合成形(Precomposed)と結合文字(Combining Character)による合成列(Composite Sequence)のコンビが多い。つまり正規等価とは、もともとは見た目だけでは区別できないこうした文字列を、うまく処理するために導入されたもののように思える(これだけが正規等価と限らないことは後述)。 一方、図2のような場合を「互換等価」(Compatibility Equivalance)と呼ぶ。この互換等価の符号同士は「同じ」であるが、正規等価とは違って同一視した場合、微妙に幅が変わったり(半角と全角の違い)、位置が変わったり(上付・下付文字と普通の文字の違い)、形が変わったり(単位記号等の合字と普通の文字の違い)することになる。つまり正規等価よりも「同じ」の意味合いが少し弱い。これが互換等価と正規等価の違いだ[*4]。 同じ「互換」が付くからと言って互換等価に指定された文字が互換用文字だけとは限らない。ここで言われている「互換=Compatibility」とは、他の文字コード規格との互換という意味ではなく、むしろUnicode内部で紛らわしく見える符号との互換(両立=Compatible)という意味のように思える。例えばキログラムを表す単位記号「kg」は単独の文字として「338F」に収録されるが、これは小文字「k」と「g」を並べた文字列と互換等価だ。同様にローマ数字の3は単独の文字として「2162」に収録されるが、これは小文字「I」を3つ並べた文字列「III」と互換等価だ。 もっとも図2で例に挙げた「半角」と「全角」カナのように、ほとんどの互換用文字とそれに対応する文字の関係が互換等価とされているのも事実だ。ということは、互換用文字は全て互換等価かというと違う。他ならぬ図3のような互換漢字は、まるごと正規等価に指定されているのだ。これがJIS X 0213の運用に問題を引き起こすのだが、それは後で説明しよう。 これら2つの属性を簡単に見分けるには、Unicode規格書にある文字表のリスト(Character Names List)を見るとよい。完全な一致を表す論理記号「≡」で別の符号に対応付けられていれば正規等価、ほぼ同じことを表わす波線のイコール(JIS X 0213面区点1-02-78、Unicodeでは2248)で対応付けられていれば互換等価だ。 ■強制的に統一した符号位置に「置き換える」正規化 ここまでは等価属性、つまり「同一視」の話だ。しかし、実際どうすれば「同じと見なす」ことができると言うのだろう? ここまで述べてきたように、Unicodeには、そのままだと重複符号化となるような、一見しただけでは紛らわしい符号の組み合わせが発生してしまう。これを等価属性にもとづいて強制的に片方に統一、置き換えてしまうのだ。これが正規化(Normalization)であり、その方法を正規化形(Normalization Form)と呼ぶ。 図1や2で挙げた上下の符号が両方混在するようなことを許しては、期待したような処理結果は得られない。そこで正規化形という「フィルター」によって、上下のどちらかに寄せて統一してしまう。「同じ」なのだから他方に置き換えてもいいというわけだ。この正規化により結果として「同じと見なす」ことになる。Unicodeでは4種類の正規化形が定められており、実装者は目的にかなった正規化形を選択することになる。ただし本稿の趣旨から逸れるため各々の詳しい説明は他に譲る。ひとまずは正規化形が4つあることを覚えておいてほしい。 ■等価属性/正規化は開国を迫る「黒船」!? さて、ここで大事なことが2つある。まず現実には正規化までしなくても、文字セットの内容によってはUnicodeは運用できてしまうと言うことだ。例えばJIS X 0201とJIS X 0208の文字集合(シフトJIS)を、Unicodeを使って符号化する場合がこれにあたる。図1では、結合文字による合成列(上)と、事前合成形の文字(下)を並べているのだが、もともと結合文字がないシフトJISのレパートリなら、こうした例は無縁と言って済ますことができる。 ではその場合、図2のような互換用文字については問題がないのか。じつは世界はUnicodeとシフトJISだけで閉じていると割り切ってしまえば、いくら片方が重複符号化を抱えていてもトラブルになることはあまりない。重複するような文字は、変換テーブルにより一対一で変換すればよい。 そういうわけで、Unicodeの実装を名乗っているからといって、等価属性/正規化まで実装しているとは限らないのが現実だ。そんな私たち日本のユーザーが、いよいよ等価属性/正規化に直面させられるのは、JIS X 0213の文字集合をUnicodeの符号化方法で実装しようとする場合だろう。 JIS X 0213にはアイヌ文字や鼻濁音といった半濁点付きの仮名が収録されている。これらは完成形としてはUnicodeに収録されておらず、結合文字を使ってしか表現できない。そこで結合文字を扱おうとした途端、二重符号化の危険性が発生する。もちろん現実には実装の抜け道はたくさん考えられる。しかし規格としてのUnicodeの回答は簡単で、等価属性/正規化を導入することに尽きる。将来を見据えれば、その場しのぎの抜け道が生産性向上に結びつかないのは明らかだ。これらの実装が、直面する課題とされる理由である。つまり等価属性/正規化は、ペリー提督の「黒船」のような存在と考えることができる。 話が脱線しかけた。さて、もう1つ重要なことがある。先に正規化とは、任意の方法で符号を置き換え・統一することと説明したが、あくまで置き換えは手段であり、目的ではないということだ。 では正規化の目的とはなにか。繰り返しになるが、文字列が互いに「同じ」かどうかを比較・評価することだ。置き換えが手段でしかないということは、例えば置き換えをした正規化文字列を一時的にメモリ上に展開し、これにより比較・評価をすることにして、元の文字列には手を付けないという処理もあり得る。 以下、互換漢字の正規化による置き換えの危険性について説明するが、正規化を施しても、必ずしもその置き換えが最終結果になるとは限らないことを留意した上で読み進めてほしい。 ■互換漢字が正規等価だと困る理由 正規化の目的は、文字列の比較・評価――これを踏まえると、例えば検索では等価属性/正規化が大切な技術であることがわかる。あるいはデータベースをはじめとした索引の作成でも同様だろう。また、比較の対象がファイル名とすれば、それはファイル管理システムで必要となる。他にもパスワードの照合、さらには、『Longhorn』における「WinFS」や、Mac OS Xの次期バージョン『Tiger』における「Spotlight」のように、ファイルのメタ情報を収集、検索しようとするものにとっても、これは大前提となる技術であることがわかるだろう。Unicodeを少しでも踏み込んで実装しようとした途端、さまざまな局面で必要となるわけだ。 そこで問題になるのは、互換漢字が正規等価になってしまった件だ。とりわけ面倒を引き起こすのは、置き換えを行なう正規化だ。 前述したように正規化の方法にはいくつか種類がある。しかし厄介なことに単一の文字が単一の文字に対して正規等価に指定されている場合(Singleton Decomposition/単一の文字への分解)は、どの種類の正規化形であっても対応する文字に置き換わることになっている[*5]。互換漢字がこれにあたり、互換漢字を正規化すると「必ず」対応する統合漢字に置き換わる。これが同じ正規等価でも、図1のように複数の符号であれば、正規化形によっては置き換わらない場合がある。また単一の文字であっても互換等価であれば、やはり置き換わらない場合もある。 Unicodeに収録された1文字ずつについて種々の情報をまとめたのが、Unicodeコンソーシアムが配布する『UnicodeData.txt』[*6]だ。等価属性/正規化に関わる情報も当然このファイルに入っている。これは公開されており誰でも入手が可能だ。タブ区切りのテキストファイルなので、表計算ソフトに読み込ませるのがよいだろう。第1カラムが符号位置、第2カラムが文字の名前。そして注目してほしいのが3つ飛ばした第6カラムの「Decomposition_Type」と「Decomposition_Mapping」だ[*7]。 この第6カラムに単一の符号位置が記載されていれば「Singleton Decomposition」だ。そして、その文字が正規等価であった場合、正規化すれば「必ず」ここにある符号位置と置き換わることになる[*8]。そして互換漢字のほとんどは、ここに対応する統合漢字[*9]の符号位置が入っている。 このようにして、もしもこの置き換わった処理結果が最終のものとなり、その後で情報交換でもすれば、元の文字は互換漢字であったという情報は永遠に失われてしまう。知らない人がこれを見れば、文字化けが起きたと思うだろう。まさにこれが互換漢字が正規等価である問題点なのだ。 次回は、Mac OS Xでの実験やマイクロソフトへの質問により、等価属性/正規化の実装における課題を考える。
◆修正履歴 [訂正1]……詳細は、特別編25の訂正3を参照されたい。(2008年9月3日)
( 小形克宏 ) 2004/09/13 - ページの先頭へ-
|