|
記事検索 |
|
|
|||||||||||||||||||||||||||||
特別編25 JIS X 0213の改正は、文字コードにどんな未来をもたらすか(8) 番外編:改正JIS X 0213とUnicodeの等価属性/正規化について(下) |
|||||||||||||||||||||||||||||
|
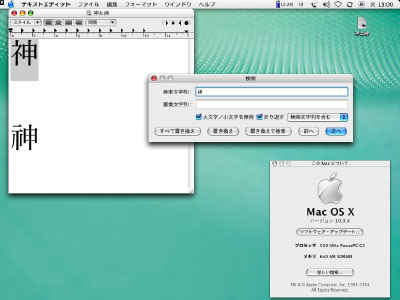
■符号表だけではないUnicodeの存在理由 前回は等価属性と正規化について説明したが、これを通してわかることは、Unicodeとは、けっして文字と符号位置の対応を規定しただけのものではないということだ。Unicodeがもくろんでいるのは世界中の文字の符号化だ。しかし本当にそれができたとしても、実装する、つまり仕事に使うためには、符号表だけではソリューションたりえない。 なぜなら文字とは、語の中での位置、文脈の種類、書き進める方向等々、さまざまな状況に応じて、思いもかけない変化をするものだからだ。だからこそ文字は生きていると言えるのだし、そうした振る舞いもそのままコンピュータ上で再現できなければ、実装することにはならないはずだ[*1]。 だから彼等は、等価属性や正規化など種々の属性にもとづく処理、あるいは対応付けを詳細に規定している。その上、それら大量の情報をすぐに引き出せるよう、データベースまで整備・開放している。 ここには全ての文字を、まるごと自分の掌中に収めるのだ、そしてそれでビジネスをするのだという、青臭い理想主義と性根の座った現実主義とが同居しているように思える。中にはSingleton Decompositionのように、わかりづらい考え方もないでもないが(なぜ「分解」が単一の文字にできるのか?[*2])、夢のような話を現実のものにしようとする努力の積み重ねには、素直に頭を下げるべきだろう。 ■Mac OS Xに見る正規等価の実装 さて、前回例に挙げた『UnicodeData.txt』[*3]は、Unicodeが整備した各種データの中でも中心的なものだ。ここにはUnicodeに収録された文字の振る舞いについての多様なデータが、アンチョコのように一覧表にまとめられている。 ただし、数年前から比べればUnicodeの実装は格段に進んだと言っても、このUnicodeData.txtに盛り込まれているようなデータまでは、なかなか実装が及んでいないのが実情だ[*4]。そんな中、このUnicodeData.txtにもとづいた等価属性の実装例として、アップルコンピュータのMac OS Xを見てみよう。まずは以下のキャプチャを見てほしい。 ■図1
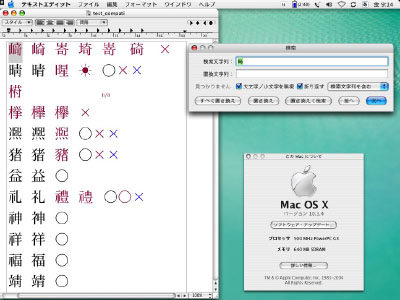
この振る舞いは、テキストエディットの検索ルーチンにおいて、互換漢字と統合漢字を「同一視」していることを示す。つまり等価属性にもとづく正規等価、つまり両者を「本質的に同じ」としているわけだ。これは、UnicodeData.txtにある通りだ。 ■等価属性をAPIレベルで実装? もちろん1組だけを調べても仕方がない。そこで改正JIS X 0213にも収録されている「IBM拡張文字」(FA0E~FA2D)と「JIS X 0213互換漢字」(FA30~FA6A)領域の文字、それに改正JIS X 0213で変更された例示字体と同じデザインの文字のうち、ヒラギノProフォントで他国の互換漢字領域に符号位置を与えられている7文字(これについては次回で詳述)をテキストエディットに入力した。そして、それぞれの互換漢字の隣にはUnicodeが対応付けた統合漢字、つまりUnicodeData.txt第6カラムの符号位置を入力する。またこれらに加え、Mac OS X『文字パレット』の「関連文字」に出現する漢字、つまりUnicodeとは別に、アップルコンピュータが独自に対応付けた文字を入力した。 そうして1文字ずつ検索をしていったのだが、その結果、他国の互換漢字領域の4文字を除けば、互換漢字は全て自分自身とUnicodeで対応付けられた統合漢字にだけマッチすることがわかった[*5]。 他国の互換漢字領域の4文字がなぜマッチしないのか不明だが[*6]、これを除けばUnicodeData.txtにある通りの振る舞いであることが確かめられた。ちなみにこの検索における振る舞いは、テキストエディットだけではなく、Mac OS X純正のメーラー『Mail』、そしてサードパーティによるエディタ『Jedit X』(ver.0.73)でも、他国の互換漢字領域の4文字はマッチしないことも含め、まったく同様に再現される。このことから見て、この検索ルーチンにおける同一視が、APIレベルでサポートされていることが推測できる。 ■この振る舞いが、あいまい検索ではない理由 多くの場合、互換漢字とそれに対応する統合漢字は異体字の関係にある。つまり、この互換漢字の例だけを見ると、異体字を同一視してくれる一種の「あいまい検索」が行なわれているように思える。しかし、それは実装者が意図したものではないはずだ。まず、対応する統合漢字以外の異体字、例えばアップルコンピュータが独自に対応付けた「関連文字」にはマッチしない。これには幅広い異体字が含まれているから、マッチすれば「あいまい検索」として便利に思う人はいるはずだ。 また、たとえ日常よく見かける異体字であっても、それがUnicodeで対応付けられていなければマッチしない。例えば、「崎」(5D0E)と人名に多く使われる異体字「タチ崎」(FA11)がそうだ(図2)。これは互換漢字「タチ崎」が独立した統合漢字と同等の文字として扱われ、統合漢字「崎」とは対応付けられていないからだろう[*7]。 ■図2
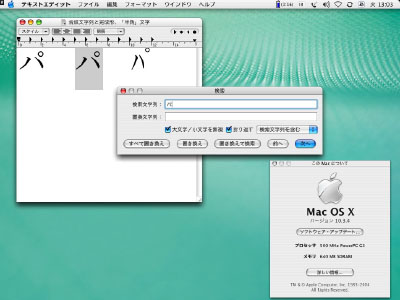
その一方、図3を見てほしい。正規等価、つまり見た目はまったく同じ結合文字による合成列と事前合成形の文字(前回、図1の例)では、互いにマッチする。しかし互換等価、つまりいわゆる「半角」と「全角」のように、文字としては同じだが、見た目が多少違うようなもの(前回、図2の例)にはマッチしない。 ■図3
この図3からわかる通り、ここで実装されているのは、あいまい検索などではない。異体字も含めてヒットしてくれてユーザーが便利に感じたとしても、それはケガの功名というべきもので、むしろ実装者は、等価属性にもとづく正規等価を忠実に検索ルーチンに反映させたかっただけではないか。もしそれがあいまい検索に見えてしまうとするなら、互換漢字の等価属性が我々の感覚とは違う指定をされているからだ。つまり、この振る舞いは、互換漢字が正規等価に指定されていることの誤りを間接的に証明している。等価属性そのものに問題があるのではなく、互換漢字が正規等価に指定されていることに問題があるのだ。 ■どの部分に正規化を適用するかの規定はない 以上、等価属性にもとづく正規等価の実装例を見てみた。もちろんこのレベルでは、あいまい検索に見えてしまう程度で実質的なトラブルはない。深刻な損失を引きおこすのは、「置き換え」をする正規化を互換漢字に対して行なった時だ。 前回述べたように、互換漢字は互換等価ではなく、正規等価に指定されているから、どんな方法で正規化を施しても、対応する統合漢字に置き換わってしまう。こうした互換漢字の「置き換え」は、互換漢字の文字の形こそが欲しい立場からすれば「よけいなお節介」でしかない[*8]。この「置き換え」られた文字列が文字処理の最終結果として確定し、画面表示されたり、印字されたりしたらどうなるだろう? もっとも、本来正規化とは文字列の比較・評価に必要な技術であるのだから、常識的に言えば、ただ文字を画面表示しようとする際には、あまり必要とはならないはずだ。後述するマイクロソフトからの回答にも見られるように、互換漢字を入力したのに、画面には統合漢字が表示されてしまうという実装は、通常は考えられない。 しかし、正規化を詳細に規定している『Unicode Standard Annex #15』[*9]では、正規化を適用する範囲まで言及はしていない。つまり、現状ではどの部分に正規化を施すかという定説はない。例えばW3Cのドラフト文書『Character Model for the World Wide Web 1.0』[*10]では、インターネット上を流れる文字列について、正規化する必要性が訴えられている[*11]。格段に広い対象を正規化せよとしているわけだ。 この文書の骨子の1つは、正規化は受信側ではなく送信側が行なうこと。もう1つはUnicodeが定める4つの正規化形のうち、使うのは任意の1つに絞ることだ(この2つをあわせ「Early Uniform Normalization/早めで一律な正規化」を提唱する)。 ということは、この文書に従うと互換漢字は統合漢字に置き換わってWebサーバーを送出され、受信側のブラウザには互換漢字は一切表示されないことになる。こうなると、実質的に互換漢字を使うこと自体ができない。このドラフト文書には大きな問題があると言わざるを得ないだろう。 ■正規化はどのように実装されるのか? 正規化を実装すれば互換漢字が使えなくなる。こうしたジレンマにアップルコンピュータも直面したのではないか。同社の開発者向け文書『Technical Note TN1150 HFS Plus Volume Format』を読むと、ファイル管理システム「HFSプラス」は、正規化を行なった上でファイル名をディスクに収納することが定められているが、2000~2FFF(各種記号類)、およびF900~FAFF(互換漢字)が使われた場合は、正規化の対象から外すことが明文化されている[*12]。つまり、ファイル管理という用途においては、特定の範囲を除外するという「独自ルール」を作っているわけだ。 調べてみると、実際にMac OS Xにおいてこれらの文字をファイル名に使っても、置き換わることなく表示される。もう一度、先の図1のデスクトップ右上を見てほしい。「神」の互換漢字(FA19)がファイル名として置き換わることなく表示されていることが確認できる。 しかしこれはあくまでアップルコンピュータの「独自ルール」に過ぎず、他のプラットフォームは無関係だ。例えば市場で過半のシェアをもつWindowsの次期メジャーアップグレード、『Longhorn』の新ファイル管理システム「WinFS」で、ファイル名の正規化が「正しく」実装されたら? これについてマイクロソフトに質問したところ、以下のような回答があった。
つまりファイルシステムにおいては、Unicodeの等価属性/正規化をそのまま実装しないと解釈できる。常識的な回答であり、どうやら安心してよさそうだ。もっとも正規化の実装が広まるのは、これからが本番だ。世の中のOSはMac OS XとLonghornだけが全てではない。また、マイクロソフトの回答の通り、これらOS上で動作するアプリケーションが正規化APIを使うかどうかは、アプリケーションベンダー次第だ。それを考えれば、等価属性におけるこれら互換漢字の扱いは、依然として課題としてあり続けるのではないか。 ■正規化を施すと、JIS X 0213にある文字が置き換わる じつは互換漢字の正規化問題はこれだけに止まらない。もうちょっとだけお付き合いいただきたい。この正規化だが、なにかJIS X 0213との関連で引っかからないだろうか? 改正されたJIS X 0213では、82文字がUnicode(≒UCS)における互換漢字に対応付けられている。そして、これらのうち56文字が法務省が定めた人名用漢字許容字体表にあるものなのだ(図4)[訂正2]。これらは法務省が常用漢字や人名用漢字とは異なる旧字体で人名に使うことを認められた法的な根拠のある文字であり、使用頻度も比較的高いものが多い。 ■図4 JIS X 0213:2004におけるCJK互換漢字の一覧(全82字)[訂正1][訂正2]http://internet.watch.impress.co.jp/www/column/ogata/sp25/zu4.htm これらの文字はUnicodeが互換漢字として収録されているというだけの理由で、正規化を施せば「必ず」対応する統合漢字に置き換わってしまう。もしもあなたの周りに、図4にある互換漢字を名前に使っている人がいたら、注意してあげた方がよさそうだ(怪訝な顔をされるのがオチだろうが)。 もちろん前回述べたように、正規化により置き換えられる文字列が処理の最終結果になるとは限らない。しかし、もし最終結果として確定した場合、それは法的な根拠のある文字が「化ける」ことを意味する。それは改正JIS X 0213の原案作成委員会はもちろんのこと、その作業を発注した経済産業省、あるいは原案作成に人を出した文化庁、総務省、そして他ならぬ法務省も望むことではないはずだ。 さて、改正JIS X 0213に対応予定であるLonghornでは、こうしたJIS X 0213に収録される互換漢字が使えなくなってしまう問題について、どのような対処を考えているのだろう? マイクロソフトに質問したところ、以下のような回答をもらった。
実際にどのように実装すれば矛盾しないのか、さらに詳しく聞きたくなるが、開発途上の現段階でこれ以上詳細な回答を求めるのは無理な話だろう。まずは同社の回答を信頼して、そのリリースを待ちたいと思う。 ■互換漢字の等価属性は、互換等価に変更されるべき もっとも、本来こうした問題を解決するのは、実装よりも規格であるはずだ。繰り返すが、互換漢字の等価属性は、正規等価ではなく互換等価に変更されるべきだ。 では、どうすればよいのか? Unicodeの審議機関であるUnicode Technical Committee(UTC)に、正会員であるジャストシステムやマイクロソフト、アップルコンピュータから働きかけてもらうのも一案だ。これはもちろん、まず我々エンドユーザーが彼等にその必要性を訴えるところから始めるべきだろう。 あるいは見方を変えてみよう。この問題は、UTCがそれぞれの文字が持つ事情をよく吟味した上で等価属性を決定しなかったから発生したのではないか。こういう場合にこそ、国内の事情をよく知る各国代表団が審議する公的規格、UCSの出番であるはずだ。UCSを審議するISO/IEC JTC 1/SC 2/WG 2委員会は、UTCと連繋しつつここまで規格を育ててきた。実際、このように重要な規定を、私企業が集まって構成されるUTCだけに負わせるのは、バランスがとれていないように思える。 もう1つ書いておきたいことがある。JIS X 0213の改正審議に携わった新JCS委員会のメンバーは、果たしてこの事態を誰も知らなかったのだろうか? 少なくとも、そのうち日本を代表してUCSの審議に参加する情報規格調査会JSC2委員を兼任する人々は、このことを知っていてもおかしくない立場にある。特にUTCのメンバーでもある小林龍生氏(新JCS委員会幹事)は、なおさらのことだ。 しかし、新JCS委員会のほぼ全ての審議を傍聴した私は、少なくとも公的な場では語られていなかったと断言できる。この原稿で今まで述べたようなことを知った上で、改正JIS X 0213のレパートリを、あえて互換漢字にマッピングし直したとすれば(改正JIS X 0213規格票、p.30~31を参照)、それは「不作為の過失」「未必の故意」とは言えないのだろうか? 今回、難解なUnicodeの規格原文に苦しみながらこの原稿を書いたのは、以上のことを言いたいがためであった。ひとりでも多くの人が、Unicodeへの理解を持つことを切に願いたい。 いずれにせよ、改正JIS X 0213の文字レパートリをUnicode上で使おうとする限り、この問題についてなんらかの対処が必要になるのは確かだ。改正JIS X 0213の普及まで、まだまだ乗り越えるべき壁は多い[*13]。
◆修正履歴 [訂正1]……図4の図版名表示に誤字があり修正した。ご教示いただいた川俣晶さんに感謝(2004/9/21) [訂正2]……図4について、ある読者の方から以下のような指摘をいただいた。(2004/9/29)
検証したところ、以上の指摘はすべて正しいことがわかった。ご指摘に感謝して訂正する。また、調べる中で他にもいくつか間違いが判明した。読者の皆さんにはお詫びして、以下のように訂正したい。
以上を修正した図に差し替えた。また、これにともない本文とキャプションを以下のように訂正する。
[訂正3]……新たに『“情報化時代”に追いつけるか? 審議が進む「新常用漢字表(仮)」』を執筆するにあたり、最新のUCSの和訳版であるJIS X 0221:2007に当たってみたところ、この原稿において非常に重要な間違いを犯していることに気付いた。2004年に私が執筆する際、参照していたUCSはその当時の最新版であるISO/IEC 10646:2003ではなく、その前の版であるISO/IEC 10646-1:2000を翻訳したJIS X 0221-1:2001だった。ISO/IEC 10646-1:2000では確かに本文で述べたようにUnicode正規化の記述はない。ところがISO/IEC 10646:2003では、新たに箇条24「Normalization forms」(P.18)として、UAX#15をそのまま引用する形でUnicode正規化を規定していた(JIS X 0221:2007では箇条25「正規形」P.28)。最新版を参照しないまま古い版を見てUCSに難癖をつけていたということであり、お門違いも甚だしい。最低限すべき努力を怠っていたことを恥ずかしく思っている。 関係者、読者の皆さまに深くお詫びするとともに、以下の1段落および関連する注釈13をそっくり削除することにしたい。なお、これに関連して元の注釈14は、注釈13に繰り上げた。(2008年9月3日)
( 小形克宏 ) 2004/09/16 - ページの先頭へ-
|