● 「分解した形」も「合成ずみの形」も「同じ字」
1990年3月、UCSと一本化する1年半前。まだ草案段階だったUnicodeは、自らの生き残りをかけて大きな変更を加える。当初からの合成列用の発音記号(結合文字)に加えて、新たに事前に発音記号を合成した文字を収録することにしたのだ。この結果、まことに面倒なことだが、Unicodeには見た目は「同じ字」なのに符号位置は「違う字」が含まれることになった。前回も述べたが一般に文字コード規格ではこれを「重複符号化」と言って嫌う。文字コード規格の本質は、ある文字の形に固有の符号に対応付けるところにあるからだ。これも互換漢字と同様、後発規格としてのUnicodeの宿命かもしれない。
これを実際の使用状況で考えてみよう。合成列と合成ずみ文字の両者が混在しているファイルがあったとして、これに対して検索をかけた場合、ユーザーが期待するのはどういう結果だろう? 見た目が同じである以上、それは片方でなく両方にマッチする結果であるはずだ。しかし検索とは見た目の文字ではなく符号位置を照合する操作だ。だとすれば片方にしかヒットしないことになってしまう。こういうところに重複符号化の落とし穴が現れる。ところが制定当初のUnicodeはこの問題に対して何の解答も用意していなかった。
1996年、Unicodeはようやくこの問題の解決に乗り出す。同年発表されたバージョン2.0で「分解した形」と「合成ずみの形」の対応を、「等価属性」として規定したのだ。Unicode規格書の文字表のリスト(Character Names List)でU+00C1の部分を見ると、分解した形であるU+0041とU+0301とが「完全な一致」を示す論理記号で対応付けられている[*1](図1下)。つまり単に対応するだけでなく「完全に同じ字」というわけだ。こうした対応をUnicodeでは等価属性と呼び、そのうちこの「完全に同じ字」のことを「正規等価」と呼ぶ。

|
|
図1 Unicodeバージョン1.0(上)とバージョン2.0(下)規格書の文字表のリストにおける、同じU+00C1の表示。1.0では個々の符号位置と文字の形、文字の名前が並んだだけなのが、2.0ではこれらに加えU+0041とU+0301との対応が示されるようになっている(『The Unicode Standard Version 1, Volume 1』The Unicode Consortium、P.178、Addison Wesley、1990/『The Unicode Standard Version 2.0』P.7~12、1996)
|
● UAX#15によるUnicode正規化の規定
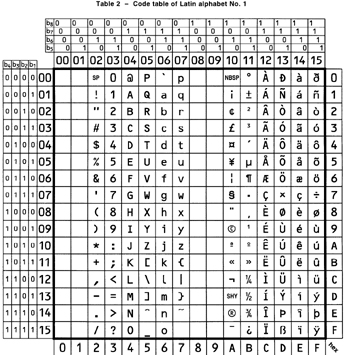
しかし「同じ」としただけでは問題が明確化されただけで解決にはならない。ついで1998年、附属文書案として『PROPOSED DRAFT Unicode Technical Report #15 Unicode Composition』が発表される[*2]。これが現在Unicode正規化を規定するUAX#15につながる最初期のドラフト提案(Proposed Draft)だ。この時点では現在の委曲を尽くしたリビジョンから見るとまだ素朴なもので、先に規定した等価属性を参照し、全部の文字列を「合成ずみの形」に置き換えるだけのものだ。どうも最初のうちはISO 8859-1との互換性確保だけを想定していたようにも思える。前述したようにこの規格は「合成ずみの形」だけを収録しているからであり(図2)、Unicodeの方でそのような形に文字列を置き換えれば、ISO 8859-1との間で一対一対応が確保されるからだ。
|
|
図2 現在のISO/IEC 8859-1の文字表。右半分を見ると発音記号付きの文字は合成ずみの形で収録されていることがわかる(『ISO/IEC 8859-1:1998』ANSI、1999年、P.5)
|
その後、同年8月のリビジョン7で、今と同じようにUnicode正規化の4つのタイプが規定されるようになり、同時に規格名が現在と同じ『Unicode Normalization Forms』になる[*3]。1999年3月のリビジョン12で「Proposed」が取れた「Draft」[*4]、同年7月のリビジョン15で正式な「Unicode Technical Report #15」として制定された[*5]。本稿執筆時点でのリビジョンが29であることからもわかるとおり[*6]、UAX#15は細かく手が加えられてきた。しかし一番本質的な部分はそう変わってはいない。
● どちらかの形に揃えて重複符号化を解消するUnicode正規化
前後してしまったが、ここでUnicode正規化について説明しよう。ここではラテン文字ではなくギリシア文字を例に説明することにする。ここには発音記号が複合する例が多く見られるからだ。プラトンやピタゴラスなどによるギリシア語古典作品は、ヨーロッパにおいては古代ローマ帝国の昔から現代に至るまで思想の背骨であり続けている。しかし、紀元前4世紀に生きたプラトンが書いたギリシア文字は、大文字だけを使い、語も区切らずに続けて書いていた[*7]。小文字の使用や語を空白で区切るのは、千数百年にわたる受容の歴史の中で主に中世の修道僧たちにより工夫されてきた表記法だった。ここで取り上げる複合した発音記号も同様だ。以下の例はバーネット版プラトン全集による『ソクラテスの弁明』書き出しの一語である[*8]。
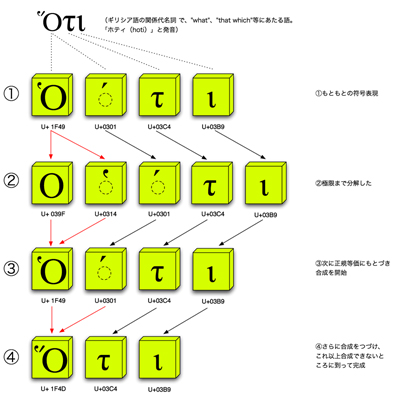
まず「合成ずみの形」に揃えるタイプの処理だ(図3)[*9]。UAX #15の当初の草案ではこのタイプだけ規定されていたことからもわかるとおり、これは前述のISO 8859-1と互換をとるために必要な処理となる。前述したようにUnicodeでは「分解した形」と「合成ずみの形」の対応を、「等価属性」として規定されている。まずこの対応を参照し、すべての文字や文字列が完全に「分解した形」になるまで繰り返し何回も分解を行う。中にはこの図のように複数の発音記号が合成されている文字もあるからだ。こうして極限まで分解した後、今度は「合成ずみの形」への置き換えを進める。この結果、全体が「合成ずみの形」に揃い、見た目は「同じ字」なのに符号位置が「違う字」は排除されることになる[*10]。
|
|
図3 文字列全体を「合成ずみの形」に揃える処理(赤線が分解・合成、黒線が不変)。ここに挙げた語の最初の文字を表現するのにUnicodeでは複数の並べ方があり得るが、ここではU+1F49とU+0301を結合させたとする(1)。U+1F49は正規等価としてU+039FとU+0314に対応付けられており、まずこれに分解される(2)。これで語全体が極限まで分解されたことになる。そこで今度はこれ以上合成できないまで合成が続けられる。(3)の段階ではまだU+1F49とU+0301が合成できる余地を残している。このような余地がなくなるまで合成は続き、最終的に(4)に至る
|
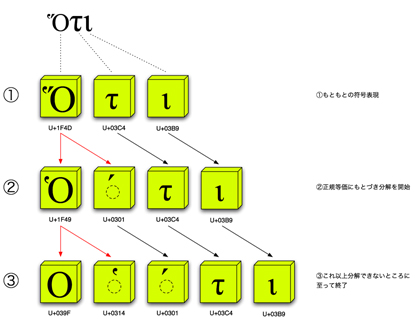
それからもう1つ、全体が「分解した形」に揃える処理も必要だ(図4)。これは前述した処理の途中段階、極限まで分解したところで止める。こうすることで全部が「分解した形」に揃い、見た目は「同じ字」なのに符号位置が「違う字」は排除されることになる[*11]。
|
|
図4 文字列全体を「分解した形」に揃える処理(赤線が分解・合成、黒線が不変)。ここでは冒頭の字を図3で最後に示したU+1F4Dから始まる文字で表現したとする。U+1F4Dは正規等価としてU+1F49とU+0301に対応付けられており、最初にこの2つに分解される(2)。しかしまだU+1F49は分解できる。これは同様にU+039FとU+0314に対応付けられ、これらに分解されたところでこれ以上は分解できなくなり、処理は終了する(3)
|
ここまでをまとめよう。発音記号付きのヨーロッパ諸語を符号化する方法には、「分解した形」の文字を収録するものと「合成ずみの形」を収録するものの2種類があり、誕生前のUnicodeはこの両方の文字を収録しないと普及が望めない状況にあった。しかし丸呑みしただけでは重複符号化になってしまう。そこで考えられたのがUnicode正規化だ。これには全体を「分解した形」に置き換える処理と、同じく全体を「合成ずみの形」に置き換える処理の2種類がある。
● 日本語の符号化でも必要なUnicode正規化
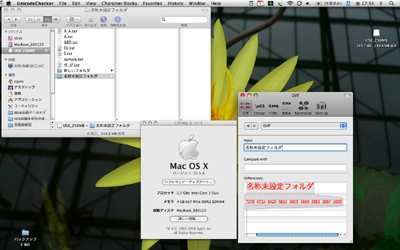
ところで、こうした問題がラテン文字やギリシア文字に固有のものと思ったら間違いだ。アラビア文字やインド系の多くの文字、あるいはハングルにも同じことが言えるし、そもそも日本語の仮名にある濁点と半濁点がそうだ。例えばAppleのMac OS XのファイルシステムであるHFS Plusでは、濁点・半濁点付きの仮名は合成列で表現するのに対し、MicrosoftのWindows XPやWindows Vistaで採用されているNTFSでは合成ずみ文字で表現する。
|
|
図5 Mac OS Xにおける濁点の符号表現。Mac OS Xで新規フォルダを作成、そこでできる「名称未設定フォルダ」という文字列を、符号位置を調べるユーティリティ「UnicodeChecker」で表示した[*12]。最後の「ダ」が「タ」(U+30BF)と結合文字「゛」(U+3099)の合成列によって表現されていることがわかる
|
|
|
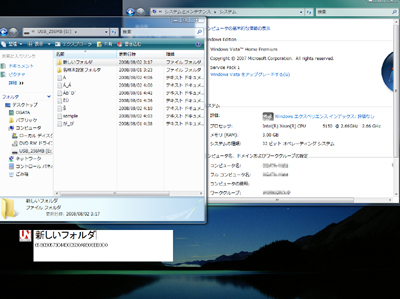
図6 Windows Vistaにおける濁点の符号表現。Windows Vistaで新規フォルダを作成、そこでできる「新しいフォルダ」という文字列を、符号位置を調べるYahoo!ガジェット「UnicodeConversion」で表示した[*13]。最後の「ダ」が合成ずみ文字である「ダ」(U+30C0)によって表現されていることがわかる
|

|
|
図7 上図を総合したMac OS XとWindows Vistaにおける濁点の符号表現の違い
|
つまりWindows VistaのユーザーがMac OS Xのユーザーから濁点/半濁点付きの仮名を含む名前のファイルを受け取ったとして、このファイル名を検索しようとした途端にUnicode正規化の処理が必要になる。もちろんUnicode正規化はどちらのOSにも実装されており[*14]、ユーザーは意識することなくその恩恵を受けている。このようにUnicode正規化は、すでに日本語のユーザーにとっても身近な技術なのである。
● 基本的な意味は同じで見た目も少ししか違わない文字を対応付ける「互換等価」
ところでUnicodeに収録された文字の中には、「全く同じ」とまでできないが、基本的な意味は同じで見た目もよく似ている文字がある。例えば日本語環境で言えば典型例が半角文字と全角文字だ。ローマ数字や多くの単位記号もUnicodeではあらかじめ1文字に合成した形が収録されているが、ラテン文字等を組み合わせても表現可能だ。他にも丸付き数字、上付文字、下付き文字、縦書き用の文字、あるいは分数やラテン文字の合字(図8)。これらは前述した発音記号付きのラテン文字や濁点・半濁点の仮名のように「見た目が全く同じ」と言えるほど「同じ」ではない。しかし置き換えても大ざっぱな意味は通るだろう。つまり文字としては「基本的に同じ」だ。

|
|
図8 Unicodeに収録されている、見た目が少し違っても文字としては「基本的に同じ」であるペアの例
|
こうした文字の場合も、検索などで同一視できると便利な場面は多いだろう。そこでUnicodeでは正規等価と同様、これらの対応も規定している。例えばUnicode規格書で半角の「ア」(U+FF71)を見ると、「近似的に等しい」を表す波線のイコールで全角の「ア」(U+30A2)と対応付けられているのがわかる(図9)。これを互換等価と呼ぶ。そしてここでは詳しく述べないが、この互換等価においても「分解した形」に揃えるタイプと「合成ずみの形」に揃えるタイプの処理が用意されている。
ここまでUnicode正規化が、Unicodeを実装する上で非常に重要なものであることを述べた。では、こうした処理が互換漢字とどのような関係があるのか、それは次回説明しよう。

|
|
図10 バーネット版プラトン全集第1巻(J. Burnet, Platonis Opera, vol. 1, Oxford Classical Texts, 1900; Imp. of 1973, St. I, p. 17[バーネット版本文の25ページ目])
|
|
現在ISO-IR(文字コードの国際登録簿)にあるギリシア語の文字コード規格は9種を数えるが、ここでもやはり合成列方式(ISO 5428/1976年登録)と合成ずみ文字方式(ECMA-118/1986年登録)の並立が見られる。一方で洋の東西を問わず古典作品のデジタル化は多くの学者たちにとっての宿望だが、特にプラトンのような高名なテキストの場合、古くからデジタル化が試みられてきた。例えばタフツ大学の『Perseus Digital Library』もその1つだが、ここで上図のバーネット版をデジタル化した『プラトンの弁明』冒頭が見られる(http://www.perseus.tufts.edu/hopper/text.jsp?greek.display=UnicodeC&language=original&navbar.display=show&doc=Perseus%3Atext%3A1999.01.0169%3Atext%3DApol.&fromdoc=null%3A)。この画面の右下に「Display Preferences」という設定項目があるが、その一番上「Greek Display」のメニューに「Unicode(precombined)」(事前合成ずみ)、「Unicode(combining diacriticals)」(発音記号を合成)という項目があることが確認できる。これらを設定することで本文で書いた「合成した形に揃える処理」「分解した形に揃える処理」が行える。この項目こそがUnicode以前から多種多様なギリシア語文字コード規格によってデータ蓄積が行われてきたこと、そしてそうした雑多な規格により符号化されたデータをUnicodeに変換するために、Unicode正規化が必要であることを物語っているのではないか。この原稿では日本語におけるUnicode正規化のマイナス面を書くことになったが、他方で過去に蓄積されたデータをUnicodeによって生かすためにこそUnicode正規化という技術が要請されてきたことを強調しておきたい。なお、ギリシア語やそれに関わるUnicode正規化については家辺勝文氏にご教示いただいた。バーネット版の提供だけでなく、『パイドロス』のパピルス写本、『Perseus Digital Library』をお教えいただいたのも氏だ。記して深く感謝いたします。
|
|
[*9]……なお、この原稿で「分解した形に揃える処理」はUAX #15での「NFC」(Normalize Form C)、「合成ずみの形に揃える処理」は同じく「NFD」(Normalize Form D)を指す。
|
|
[*10]……規格の上からは結合文字と合成可能な基底文字は広く規定されている。例えばMac OS Xにおいては、結合文字はラテン文字はもちろんカギカッコとさえ合成する。つまり「合成ずみの形」の数以上に「分解した形」があり得るし、Unicodeの中では「合成ずみの形」と「分解した形」は一対一対応にはならない(後者の方が多い)。したがって全部の文字を「合成ずみの形」に揃えることは本来不可能であり、規格もそこまで意図していないと言える。正確な表現としては〈可能なかぎり「合成ずみの形」に揃える〉ということになるだろう。
|
|
[*11]……ここではUAX#15に基づきUnicode正規化の考え方を説明している。実装においては必ずしもここでの説明どおりに処理されているとは限らないことに注意。
|
|
[*12]……『UnicodeChecker』earthlingsoft(http://earthlingsoft.net/UnicodeChecker/)
|
|
[*13]……『UnicodeConversion』Sean McLennan(http://widgets.yahoo.com/widgets/unicodeconversion)
|
|
[*14]……「OS付属のテキストエディタで、発音記号付きラテン文字の合成列/合成ずみ文字を同一視するか」というテストを行ったところ、Mac OS X(ver.10.5.4)、Windows Vista(ver.6.0 Home Premium)ではともに同一視するが、Windows XP(SP3 Home Edition)では同一視されないことが確認できた。このテストだけでははっきりしたことは言えないが、Windows XPではUnicode正規化は一部の実装にとどまっているのかもしれない。なお、図6のWindows Vistaで作成した「新しいフォルダ」という文字列をMac OS Xに持ってきてUnicodeCheckerで調べると、「ダ」は分解した形に置き換わっていることがわかる(図11)。一方で図5のMac OS Xで作成した「名称未設定フォルダ」という文字列をWindows Vistaに持ってきてUnicodeConversionで調べると分解した形のままであることがわかる(図12)。またWindows XPにおいてもWindows Vistaと同じことを試したところ、やはり同じ結果だった(図13)。これらの結果からすると、HFS PlusではUnicode正規化を行っているのに対し、NTFSでは行っていないように見える。
|
|
|
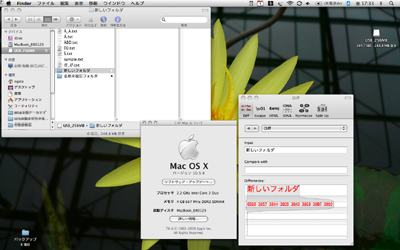
図11 Windows Vistaで作成した文字列をMac OS Xに持ってくると分解した形に変換している
|
|
|
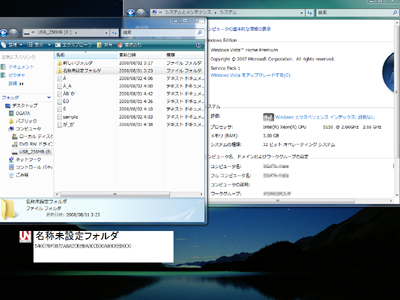
図12 Mac OS Xで作成した文字列をWindows Vistaに持ってくると分解した形のまま
|
|
|
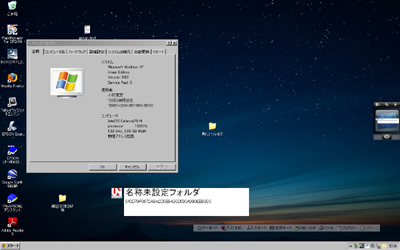
図13 Mac OS Xで作成した文字列をWindows XPに持ってくると分解した形のまま
|
|
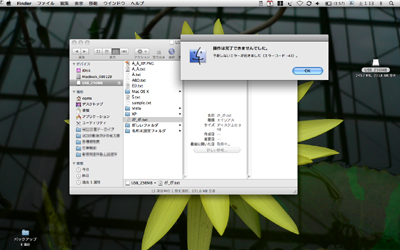
ただし、HFS Plusにも不思議な振る舞いはある。Windows Vistaで合成列を含むファイル名を作成し(内容はテキストファイル)、これをMac OS Xに持ってくると、ファイルの種類がエイリアスとなって開くことも削除することもできない(図14)。サイズや作成日も正しく表示できない。ファイルの認識そのものに失敗しているように見える。
|
|
|
図14 Windows Vistaで作成した合成列を含むファイル名を付けてMac OS Xに持ってくると、ファイルを開けない
|
|
一連のテストを通じて言えることは、Unicode正規化の実装といってもOSの種類やそのバージョンごとにさまざまであり、いまだ十全な実装がされているとは言えなさそうだということだ。
|
2008/09/04 12:02
 |
小形克宏(おがた かつひろ)
文字とコンピュータのフリーライター。本紙連載「文字の海、ビットの舟」で文字の世界に漕ぎ出してから早くも8年あまり。知るほどに「海」の広さ深さに打ちのめされています。文字ブログ「もじのなまえ」ときどき更新中。 |
- ページの先頭へ-
|
