|
記事検索 |
バックナンバー |
【 2009/04/09 】 |
||
| ||
【 2008/11/28 】 |
||
| ||
【 2008/11/27 】 |
||
| ||
【 2008/11/14 】 |
||
| ||
【 2008/11/13 】 |
||
| ||
【 2008/11/12 】 |
||
| ||
【 2008/11/11 】 |
||
| ||
【 2008/10/31 】 |
||
| ||
【 2008/10/30 】 |
||
| ||
【 2008/10/29 】 |
||
| ||
【 2008/10/28 】 |
||
| ||
【 2008/10/27 】 |
||
|
|
|
||||||||||||||||||||||||||
| “情報化時代”に追いつけるか? 審議が進む「新常用漢字表(仮)」 |
||||||||||||||||||||||||||
|
第2部 新常用漢字表と文字コード規格 |
||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||
|
● “情報化時代”の新しい文字 前回は符号位置の並びが違っても「全く同じ」字である「正規等価」、それから符号位置の並びが違い、正規等価ほど「同じ」とはできないが、「基本的な意味は同じ」で見た目もあまり変わらない「互換等価」、そしてこれらに基づいて重複を排除するUnicode正規化について述べた。例えば、文字コードのことを活字棚に喩え、棚に並べられている活字に1つずつ番号を振ったようなもの……とするような説明を耳にしたことがないだろうか。しかし現在私たちが使っているコンピュータに実装されたUnicodeは、すでにそうした牧歌的な喩えでは正確に理解することはできない。見た目だけを比べると「全く同じ字」でも、背後に振られた番号からは「違う字」という場合があるのだし、そもそも1個の「番号」が必ず1文字に振られているとは限らない。つまり画面に映し出されたり紙に印刷された文字の「形」だけに囚われていると理解を誤ってしまう。Unicodeを見ていると、これは従来と全く枠組みが違う“情報化時代”の新しい文字であるように思える。 ここで思い出してほしいのが互換漢字だ。これらはUnicodeの統合規則から言うと本来は収録されるはずがなかったが、さまざまな事情により既収録の統合漢字と区別する必要があって収録された文字だ。一方で、互換等価とされている文字たちも、やはり見た目は少ししか違わないが何かしら区別する必要があって収録された文字であるはずだ。ということは互換漢字は当然「互換等価」でなければならないことになる。では実際にUnicode規格書で互換漢字の属性を確かめてみよう(図1)。
● パンドラの箱を開けてしまったJIS 「完全な一致」を示す論理記号で対応付けられていることからわかるとおり、互換漢字は正規等価に指定されている。そしてUnicodeでは単一文字が正規等価として単一文字に対応付けられている場合は、どのタイプのUnicode正規化を行っても対応する文字に置き換わると規定されている(これをSingleton Decomposition/単一文字への分解と呼ぶ)[*1]。こうして互換漢字はUnicode正規化を行った途端、強制的に対応する統合漢字に置き換わってしまうことになるのである。残念ながらこの互換漢字の正規等価の属性は、将来も修正されないと思われる。すでにUnicode正規化の実装は普及し始めており、それらの実装との互換性を保証するためにも変更はできないからだ。これはUnicodeでは『Unicode Character Encoding Stability Policy』(Unicode符号化における安定化の指針)の中で、「Normalization Stability」として明確に規定されている[*2]。 まるで狐につままれたような話だ。図1のJIS X 0213の文字はいずれも人名用漢字、つまり日本の政令に根拠を持つ漢字だ。それがUnicode正規化を行うことで、字種は同じとはいえ別の字体に置き換わってしまう。日本人としては非常に困るし、何とか修正できないかと思ってしまう。実際にJIS X 0213の互換漢字がUCSで審議中の段階から、この問題を予見して互換漢字の属性を互換等価に変更するようUnicodeに働きかける動きが日本人を中心にあったのだが、残念ながら結果として修正されないままに終わってしまった。 こう書くとUnicodeばかりが悪いようだが、彼らの側にも同情すべき点はある。Unicode正規化を定めたUAX#15が制定された1999年は、互換漢字の性格が明確化される議論がちょうど始まったころだった。というより、UCSが初めて互換漢字の厄介さに気付いた時期と言えるかもしれない。このころの議論の中で既存の互換漢字と対応する統合漢字について洗い直しが行われ、その結果、対応するものがない互換漢字については、統合漢字と見なすことが決定された[*3]。 第3回で述べたような「互換漢字は特定の規格との互換性確保だけに使われるもの」という位置付けも、この時の議論によって明確化されたものだ。実際にこの条項はUCS(ISO/IEC 10646)の2000年版にはなく、2003年版で初めて付け加えられている[*4]。こうした議論が定まらないうちにUAX#15は制定された。そのころのUnicodeにとっては、互換漢字が正規等価だろうが互換等価だろうが大差はないと思われていたのではないか[*5]。 ということは、そうした互換漢字に政令文字を割り当てたJIS X 0213が犯人なのだろうか? もちろん違う。そもそも法務省がこれらの字を人名用漢字(当時は人名用漢字許容字体)に指定しなければ、JIS X 0213は互換漢字に割り当てなかったはずだからだ。では法務省が犯人? 違う、法務省が悪いわけではない……とまだまだ先は続く。このことが何を意味するか第3部で考えることにして、今は先を急ごう。 ● 互換漢字を置き換えてしまうDTPソフト では、こうした互換漢字の置き換えが、私たちにとってどのような影響があるのだろう。それを考える上で注意すべきは、Unicode正規化の本来の目的は文字や文字列同士が同じかどうかという「照合」であり、したがって必ずしもユーザーが目にする画面表示や印刷にまで及ぶ必要はないということだ。例えばMac OS X付属のテキストエディットでは、検索にUnicode正規化を取り入れていることで知られている(図2)。
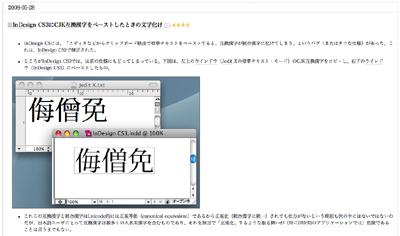
ここでは、検索の処理過程においてメモリ上にファイルを書き出してUnicode正規化を施し、これに対して検索を行うことで、画面上では置き換えた結果そのものは目に入らないようにしていると思われる。このようにUnicode正規化は、Unicodeによる文字列の照合が必要となる操作全般で必要とされている。検索、置換、整列、そしてファイルをHDDなどに収納するファイル管理システムなどでも実装されている。しかしUnicode正規化が図2のように「裏方」に徹している限り、いくらこれを規定したUAX#15の規定上では互換漢字が必ず置き換わると言っても、ユーザーが編集しているファイルの中身にまで影響を及ぼすことはない。 しかし、そのようなアプリケーションばかりとは限らないのが現実だ。例えばDTPソフトで大きなシェアを持つアドビシステムズのInDesign CS3を見てみよう。直井靖氏が自らのブログで報告したところによれば、Mac OS X版のInDesign CS3に一定の条件下で互換漢字をペーストすると、対応する統合漢字に置き換わってしまう。
直井氏がこの日のエントリで書くように、文字の形が業務に直結するプロフェッショナル向けDTPソフトで、何のアラートも出さずに人名用漢字を含む文字を置き換えてしまうような振る舞いは、ユーザーにとってきわめて危険なものと言える[*7]。それでも、アドビシステムズは互換漢字を置き換えるためにこうした実装を行ったのではないのだろう[*8]。おそらくは、前述した発音記号付きのラテン文字を、アプリケーション上で扱いやすい合成ずみ文字に置き換えることが本来の目的だったはずであり、その限りではUnicode正規化の目的にかなった真っ当な実装とすら言える。同社にとって互換漢字が置き換わることの方が想定外だったのかもしれない。 ● Unicode正規化が必要とされるインターネットの現実 こうしたInDesign CS3の実装がユーザーにとっては迷惑であっても、じつはUnicodeの規定上は問題がない。もともとUAX#15にはどの部分に対してUnicode正規化を行うとする規定はなく、置き換えた結果をユーザーに見せてはいけないというような規定もない。だから実装者は目的に合わせてどのように実装してもよい。では、このことが何を意味するのだろうか。ここまではアプリケーション上の検索やカット&ペーストなど、ユーザーのローカルな環境に限定した例ばかりを挙げてきた。しかし現代では符号の処理が1台だけにとどまることの方がむしろ珍しい。私たちのコンピュータはたいていの場合ネットワークに接続されており、そこで入力した文字は深く意識することもなくネットワークを駆けめぐっている。じつをいうとUnicode正規化はこうしたインターネット時代(漢字小委員会ならこれを“情報化時代”と呼ぶはずだ)にこそ必要とされる技術だ。 このことは時間を少し戻してみるとよく理解できる。インターネットが登場するずっと以前、例えば大型計算機やテレタイプといった旧来型のネットワークでは、符号を送る側と受ける側には完全な合意が存在した。一つ一つのネットワークは独立していて、その内部では特定のメーカーのハードウェアが使用される。だから符号の受信にあたっては特定の相手から特定の種類の符号が送られてくると割り切ることが可能だった。 しかし1990年代前半以降、インターネットが急速に普及したことにより事情は大きく変わった。ここではネットワークを構成するハードウェアは種々雑多であり、不特定多数との合意のない情報交換を想定しなければならなくなった。具体的にいえば 前回調べたMac OS XとWindows Vistaの符号表現からもわかるように、送信相手が「ダ」という文字を表すのに合成ずみ文字のU+30C0を使うのか、それとも合成列のU+30BF/U+3099を使うのか、前もって予想はできないというのがインターネットにおける情報交換だ。Unicode正規化はまさにこうした状況の中で必要性が高まってきている。逆にいえばかつてのような大型計算機やテレックスなどのように秩序立った環境では、Unicode正規化は必要とされなかっただろう。 次回は具体的にどのような用途でUnicode正規化が必要とされているのかを見てみることにしよう。
● 修正履歴 [訂正]……安岡孝一氏より、ご自身のブログ『yasuokaの日記』を通して、この原稿に対してコメントをいただいた(2008年9月4日付エントリ「人名用漢字と互換漢字」http://slashdot.jp/~yasuoka/journal/451203)。これについて調べ直したところ、安岡氏のおっしゃる通り、〈1999年当時、話がそんなに簡単だったわけではない〉ことがわかった。このエントリは直接的には第2部第5回について書かれているのだが、むしろ第2部第7回の下記部分を訂正するべきと判断した。詳細は訂正部分をお読みいただきたいが、互換漢字は1999年当時、その性質についてちょうど再定義が始まったころであったと考えられる。JIS X 0213互換漢字は、そうした状況の中で提案、審議、承認された。またUnicode正規化を規定するUAX#15(1999年制定)も、同様にこの時期に制定されたものだ。これを私は見落としていた。安岡氏をはじめ関係者の皆様にお詫びするとともに、以下のように原稿を訂正したい。
(2008/10/11) 2008/09/05 11:07
- ページの先頭へ-
|