|
記事検索 |
バックナンバー |
【 2009/04/09 】 |
||
| ||
【 2008/11/28 】 |
||
| ||
【 2008/11/27 】 |
||
| ||
【 2008/11/14 】 |
||
| ||
【 2008/11/13 】 |
||
| ||
【 2008/11/12 】 |
||
| ||
【 2008/11/11 】 |
||
| ||
【 2008/10/31 】 |
||
| ||
【 2008/10/30 】 |
||
| ||
【 2008/10/29 】 |
||
| ||
【 2008/10/28 】 |
||
| ||
【 2008/10/27 】 |
||
|
|
|
|||||||||||||||||||||||||||
| “情報化時代”に追いつけるか? 審議が進む「新常用漢字表(仮)」 |
|||||||||||||||||||||||||||
|
第2部 新常用漢字表と文字コード規格 |
|||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||
|
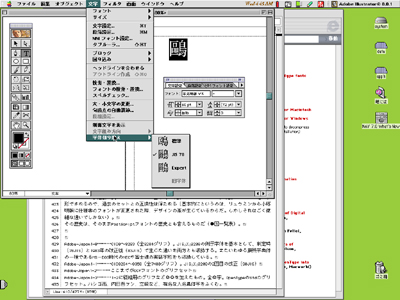
● 国際化ドメイン名で互換漢字が使えない理由 Unicode正規化が規格に盛り込まれている例として、国際化ドメイン名(IDN)が挙げられるだろう。ドメイン名はいわばインターネット上の番地表示だが、従来はラテン文字のaからz(大文字/小文字は区別しない)、数字の0から9、それにハイフン「-」の計37文字だけに限定されていた。国際化ドメイン名とは、これをUnicodeの範囲に拡大し、それにより世界の人々が自分の使っている言語でドメイン名を表現できるようにしようとするものだ。具体的にはインターネットの規格であるRFC 3490~3492の3つで規定されている。ここでは「Punycode」(RFC 3491[*1])と呼ばれる一定の規則に従って、Unicodeの文字列を現在使われている37文字に変換することにより国際化ドメイン名が実現されている。しかしこの変換をする前に「Nameprep」(RFC 3492[*2])と呼ばれる手順に従って前処理を施すことになっている。これは「Stringprep」(RFC 3454[*3])の中で示されたテキスト処理の枠組みを使っているが、その中でUnicode正規化が指定されている[*4]。 なぜ国際化ドメイン名でUnicode正規化が必要なのか。考え方としては今まで繰り返してきた説明と全く同じだ。例えば「ダ」を表すUnicodeの文字が、合成ずみ文字のU+30C0を使うのか、それとも合成列のU+30BF/U+3099を使うのかによってPunycodeの変換結果が変わってしまう。Punycodeはあくまで任意の符号を特定の範囲の符号に変換するだけのもので、符号に割り当てられた文字の意味や属性まで考慮してはいないからだ。こうして違うPunycodeの並びになり、結果として「見た目は同じ」なのに違うドメイン名が登録できてしまう。本来ドメイン名はインターネット上で唯一のものでなければならず、もしそのような紛らわしいドメイン名が存在してしまえば、ユーザーが混乱するのはもちろん、フィッシングサイトなどの犯罪を誘発することになる。そこでUnicode正規化を含む前処理によって「ネットで使える字」に置き換える処理が必要になるというわけだ。 ● 常用漢字が互換漢字になれば、日本語JPドメイン名は板挟みに ただし、日本語JPドメイン名としては、現在のところ使用を許された文字の範囲をJIS X 0208にある平仮名、片仮名、漢字、一部の記号に限定しており、JIS X 0213で拡張された範囲は使用できない[*5]。つまり互換漢字はUnicode正規化以前に、この字種制限にひっかかって使えない。なぜ日本語JPドメイン名にJIS X 0213が使えないのだろう。これについてJPドメイン名を管理している日本レジストリサービスの米谷嘉朗氏にお聞きしたところ、その理由としてJIS X 0213が十分に普及していないこと、ユーザーからJIS X 0213を使いたいとの要望がないことの2点を挙げた。まだJIS X 0213に対応したWindows Vistaが普及していないことが大きいと考えられる。しかし、反面から言えば3年後もWindows Vistaが現在のような普及状況にあるとは思えない。さらに、常用漢字表で追加された字がJIS X 0213でなければ使えない状況になれば、どうなるだろうか? 例えば第2部第1回で述べた、点なしの「箸」が新常用漢字表に追加されたとしよう。この結果、多くの人々からドメイン名をはじめさまざまな場面で点付きと点なしの「箸」を区別したいという要求が増大するようになるかもしれない。しかしこれは現在のUCSでは区別できないので、やむなく互換文字として追加提案することになる[*6]。非漢字圏諸国の抵抗はあるだろうが、何とかそれをはねのけて互換漢字としてうまく収録できたとしよう。UCSに収録できればJIS X 0213も追加できる[*7]。JIS X 0213が改正され、Windows VistaやMac OS Xなど主なOSもこれを実装し、その普及を見極めれば日本語JPドメイン名のルールも変更可能な状況になる。 しかし最後の段階でUnicode正規化が立ちはだかることになる。前述したように国際化ドメイン名がNameprepを使う限り、互換漢字は対応する統合漢字に置き換えられる。しかしその互換漢字は他ならぬ日本の漢字政策の中心である常用漢字なのだ。さて、どうする? これについて再び日本レジストリサービスの米谷氏にお聞きしたところ、次のような回答が返ってきた。「それは……非常に難しい質問ですね。常用漢字という属性の文字が互換領域に入ってしまったら、おそらく日本としては互換領域の漢字を国際化ドメイン名に使える文字に追加するよう、働きかけざるを得なくなります。ただ、それが国際的な理解を得られるかどうかは全く自信がありません」。 つまり日本語JPドメイン名の管理者としては、常用漢字表を推し進める国語施策と、紛らわしい文字は使わないようにしようという国際的な動きとの間で板挟みになってしまう。同情せざるを得ないのは、彼等自身はこの板挟みを打開する立場にないということだ。本当に常用漢字が互換漢字になってしまえば、気の毒なことにその結末は今の彼等に予測できない。本当に、どうなってしまうのだろう? ● インターネット標準に広がるUnicode正規化 ここで注意してほしいのは、こうした「紛らわしい字を排除したい」という要求は、国際化ドメイン名に限った話ではないということだ。この要求はインターネットの発展とともに増えることはあっても減ることはない。実際にUnicode正規化を組み込むRFCは増えてきている。そうしたRFCが普及するにつれて、ネットワークの伝送経路上のどこでUnicode正規化が行われているかわからないことになる。その結果、互換漢字は、いつ、どのようなタイミングで別の字体に置き換わるかわからない、不安定な位置付けの文字となる。例えばIDとパスワードだ。このような重要な文字列こそ「見た目は同じ字」が排除されなければ、犯罪者がつけ込む隙を許すことになる。これをUnicodeの文字として使う規格は、すでにRFC 4013「SASLprep: Stringprep Profile for User Names and Passwords」として制定されているが、やはりここでもUnicode正規化が要求されている[*8]。 また、現在ドメイン名と同じく37の文字種の範囲に制限されているURLだが、これもUnicodeの文字列を使用できれば、もっと直感的でわかりやすくなるだろう。これもすでにRFC 3987「Internationalized Resource Identifiers(IRIs)」として制定されているが、同じくここでもUnicode正規化が要求されている[*9]。またStringprepに関しては外部記憶装置のプロトコルであるSCSIをTCP/IPで利用するiSCSIという技術がある。この中でRFC 3722として、デバイス名の文字列をStringprepの枠組みによりUnicode正規化することが規定されている[*10]。このようにUnicode正規化はインターネット標準の中ではますます重要になってきている。 実際にはこれらのRFCは、まだ広く普及する状況にはなっていない。例えばIDやパスワードのようなミッションクリティカルな文字列は、文字種を狭く制限しておいた方が安全だというような事情もある。セキュリティホールを突かれたことによる訴訟リスクを覚悟してまで、IDやパスワードに使える文字種をUnicodeにまで拡大する現実的メリットは、今のところはない。しかし、常用漢字表に新しく文字が追加されたらどうなるだろう? 国語施策の基本である常用漢字表に追加されれば、世間の人々もこれをIDなどに使いたいと望むだろう。しかし、その文字が互換漢字として収録される限り、使うに使えない文字となってしまう。これが“情報化時代”の現実だ[*11]。 ● 互換漢字に代わるUnicodeからの提案「異体字シーケンス」とは 互換漢字が置き換わってしまう理由は、Unicodeで正規等価の属性を指定されているからだということは、前回述べたとおりだ。こうした状況の中で、互換漢字に代わる解決法として注目を集めつつあるのが、第2部第4回で少しだけ出てきた「バリエーション・シーケンス」(Ideographic Variation Sequence。以下、異体字シーケンスに統一[*12])だ。これはSun Microsystems(当時)の樋浦秀樹氏とAdobe Systemsのエリック・ミューラー氏の提案によって、2006年にUnicode Technical Standard #37として制定されたものだ[*13]。技術的な詳しいことは後述するとして、これの肝と言える点は「従来は包摂されていた字体を区別可能にする」ところにある。これまでも文字コード規格で符号化されている文字の異体字を使用可能にする技術は、Adobe SystemsのIllustrator 5.5(1994年)でCIDフォントを使って実現した「字体切り換え」をはじめ(図1)、かなり以前から試みられてきた。Mac OS Xでは2000年のパブリックベータ版から、ファイル形式のRTF(Rich Text Format)を独自拡張し、ヒラギノフォントに内蔵された符号位置を持たない文字を入力・編集・印刷可能にしている。最近では一太郎2008がMSフォントを使った異体字入力機能を搭載している[*14]。
これらはあらかじめフォントに内蔵された符号位置を持たない文字の形を、アプリケーションの機能を使ってファイルに埋め込むという点で共通している。つまりフォントに依存した独自のファイル形式により実現する方法だ[*15]。したがって、どうしても汎用性という意味で問題が残る。異体字シーケンスはこれを解決しようとするものだ。 異体字シーケンスも入力や再現には対応したフォントとアプリケーションが必要となるのは同じだ。しかしファイル形式はUnicodeの符号が並ぶだけの、レイアウト情報を含まない単純なプレーンテキストだから、たいていのアプリケーションで普通に扱うことができる。もし異体字シーケンスに対応していない環境であっても、従来の方式と違い文字が欠落したりせずに、対応する統合漢字(異体字)が表示されるにとどまるとされる(この点は第10回に検討する)。 次回は、もう少し詳しく異体字シーケンスの規格と運用を見てみよう。あわせて、これが本当に互換漢字の代替になり得るのかを考えなければならないが、これはそのまた次の第10回で触れる予定だ。
2008/09/08 15:58
- ページの先頭へ-
|