|
記事検索 |
バックナンバー |
【 2009/04/09 】 |
||
| ||
【 2008/11/28 】 |
||
| ||
【 2008/11/27 】 |
||
| ||
【 2008/11/14 】 |
||
| ||
【 2008/11/13 】 |
||
| ||
【 2008/11/12 】 |
||
| ||
【 2008/11/11 】 |
||
| ||
【 2008/10/31 】 |
||
| ||
【 2008/10/30 】 |
||
| ||
【 2008/10/29 】 |
||
| ||
【 2008/10/28 】 |
||
| ||
【 2008/10/27 】 |
||
|
|
|
|||||||||||||||||||||||||||||||||||
| “情報化時代”に追いつけるか? 審議が進む「新常用漢字表(仮)」 |
|||||||||||||||||||||||||||||||||||
|
第2部 新常用漢字表と文字コード規格 |
|||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||
|
● 任意の字体を表示させる手段としての異体字シーケンス 第2部第8回で異体字シーケンスの一番の肝は「従来は包摂されていた字体を区別可能にするところ」と書いた。つまり従来の異体字シーケンスに対応しない環境では、フォントを切り替えれば包摂の範囲内で字体が変わっても仕方なかったのを、これを使うことによって強制的に任意の字体を表示させることができる。しかもこれに対応した環境同士ならば、そうした区別を保持したままプレーンテキストによる情報交換をし、そのままの字体で表示が可能だ。UTS#37では以下のような例を挙げ、異体字シーケンスを使えば「芦」という漢字の異なる2つの字体を使い分けられると説明している(図1)。
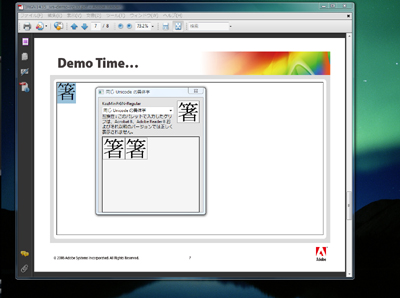
ここまで何回も例に挙げた「箸」の場合でいえば、前回述べたようにフォントを切り替えると点つきになったり点なしになったりしてしまうのが現状だった。これが異体字シーケンスを使うことで、表外漢字字体表に基づいた点のある方の字体を強制的に表示させることができるようになった。異体字シーケンスに対応し、Adobe-Japan1に準拠した異体字シーケンス対応フォントを使用する限り、フォントを切り替えても必ず印刷標準字体が表示されるようになる。これが普及すれば現状の「混乱」も解消に向かうということだろう。 ● アプリケーションやOSにおける異体字シーケンスの実装 Adobe Systemsは最近発表されたAcrobat 9、Adobe Reader 9、およびAdobe Flash Player 10で、異体字シーケンスに対応している[*1]。よく知られているようにAdobe Reader 9は無料で入手可能だ。手近に異体字シーケンスを試すには、これとUCSの漢字レパートリを審議するIRGの第30回釜山会議で公開されたケン・ランディ氏(Adobe Systems)によるPDF文書、『Ideographic Variation Sequences - Implementation Details & Demo -』の7ページ目にあるフォームフィールドを使用するとよいだろう(図2/注釈1参照)。
同時に公開された『White Paper: Ideographic Variation Sequences』は異体字シーケンスの規格と実装情報を簡潔にまとめた資料だ[*2]。ここではOSの対応について以下のように書いている。
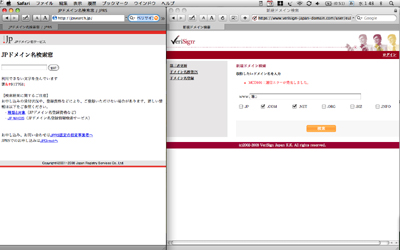
また前掲『Ideographic Variation Sequence』の中でも「Microsoft & Apple Are Fully Aware Of IVSes」(MicrosoftとAppleはIVSを完全に知っている)と書いている。このうちAppleはすでに2000年2月の時点から異体字シーケンスに対して将来実装する意向を示していた[*4]。後で述べるようにMac OS Xのテキストエディットは異体字シーケンスに対応はしていないが字形選択子の解釈はしている。こうしたことからすれば、Mac OS Xで異体字シーケンスが使える日は意外に近くまで来ているように思える。またAdobe Systemsがここまで言うからには、恐らくWindows Vistaでも使えるようになるのではないか[*5]。 ● 「包摂字体を区別する技術」を使ってはいけない分野がある 以上、異体字シーケンスが目指すものを説明した。そこでこれが一般に普及する前に、何か問題がないか検討してみよう。まず懸念材料として挙げられるのが、異体字シーケンスも互換漢字と同様、国際化ドメイン名(IDN)に使用できないということだ。字形選択子は第2部第8回で述べた国際化ドメイン名を規定するインターネット標準(RFC)の中で、削除される文字に指定されている。具体的にはそれらの中で引用されている文字処理の枠組み「Stringprep」(RFC 3454[*6])の中で、Unicode正規化の他にもいくつかの文字をあらかじめ削除する処理を規定しており、その中に字形選択子が入っている[*7]。ただし、ここで指定されているのは異体字シーケンスに使う第14面のU+E0100~U+E01EFではなく、BMP(第0面)にあるU+FE00~U+FE0Fだけだ。これはStringprepが対象とする文字セットの範囲を2002年3月制定のUnicodeバージョン3.2に制限していることによる。第14面の字形選択子がUnicodeに収録されたのは2003年4月のバージョン4からなのだ[*8]。 もともとStringprepの目的は、紛らわしい文字を排除するところにある。第8回でも説明したが、「見かけはそっくりだが符号の並びは違う」というような紛らわしい文字が存在すれば、例えば外見は同じなのに違うドメイン名が登録されてしまう。「箸」の例でいえば、仮にこの字を含んだ箸や折り箱の老舗があったとして、悪意のあるライバル店は異体字シーケンスを使うことで簡単に偽ドメイン名を登録できてしまうことになる。こうした紛らわしい文字の排除は、一部の用途にせよきわめて緊急性の高い課題だ。 つまり、Stringprepによる字形選択子を削除するという処理そのものは正しいと言わざるを得ないし、この意味からは国際化ドメイン名に異体字シーケンスは使われるべきではない。したがって将来Stringprepの対象文字セットが拡大される際には、U+E0100~U+E01EFの字形選択子が削除対象に追加されると思われる。 では現在、異体字シーケンスを含む日本語ドメイン名は登録できるのだろうか。日本レジストリサービス(.jpを管轄)とVeriSign(.com、.netを管轄)のドメイン名検索ページで、「箸」の異体字シーケンス「U+7BB8/U+E0101」で検索してみたところ、前者は「利用できない文字を含んでいます」、後者は「通信エラーが発生しました」という表示がされた(図3)。これらの検索画面で利用可能と認定されなければ手続きが進められないため、現状でも異体字シーケンスを含む日本語ドメイン名は登録できないと考えてよさそうだ。
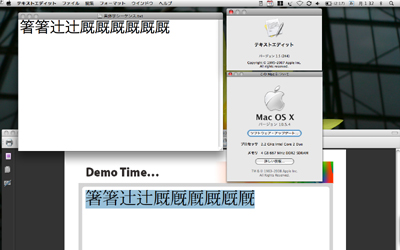
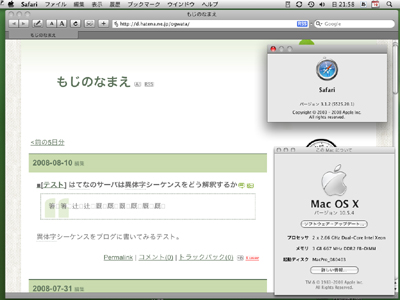
ここで明らかになるのは、個別の規格であるStringprepの中で字形選択子が削除されるかどうか以上に、むしろ異体字シーケンスという技術そのもの、あるいは包摂字体を区別したいという要求そのものもがセキュリティ問題を発生させる可能性があるということだ。もっともこれは異体字の問題もさることながら、片仮名の「ニ」と漢字の「二」、同様に「ロ」と「口」の例が示すように、日本語そのものが持つセキュリティ問題とも言える。それでもこれは包摂とは何か、何のためにあるのかを考えさせてくれる事例ではある。 ● アプリやOSには「デフォルト無視可能」でも、ユーザーは無視できない もう1つ、UTS#37が言う「デフォルト無視可能」にも注意する必要がある。例えばMac OS Xでは、現状でも字形選択子はたいていの場合は不可視だし(図4)、普通には入力もできない。
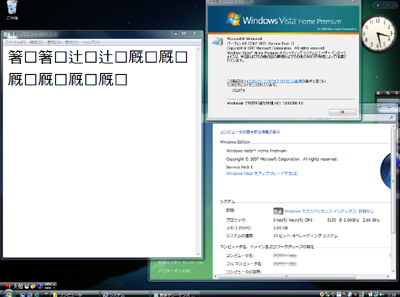
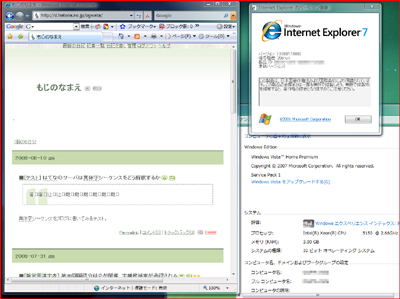
しかしこれは、あくまでそのように実装されているからだ。字形選択子がUnicodeに収録される2003年4月以前から稼働しているようなサーバーやOS、アプリケーションなどに対し、最先端のOSと同じ振る舞いを要求すること自体が無理な話だ。また最新のOSといっても必ず不可視にするわけではない。Windows Vistaで図3のテキストファイルをメモ帳で読み込んでみたところ、以下のような結果となった(図5)。
「無視」がどの程度のレベルを指すかにもよるだろうが、少なくとも字形選択子を不可視にするには、それなりの実装が必要であることがわかる。もう少し試してみよう。前掲図3~4で使用した文字列をブログにペーストしてみた。これをブラウザで読み込むとどうなるだろう(図6~8)。
UnicodeChecker自体は字形選択子を不可視として処理するだけだから、一見すると「Input」と「Compare with」に表示された漢字は全く同じに見える。しかしじつは符号の並びは違う。赤字の「U+DB40」で始まる符号の並びはいずれも字形選択子のサロゲートペア(第2部第9回の注釈3参照)による表現。すなわち、ブログサーバーもブラウザも字形選択子を削除したり不可視の文字に置き換えたりせず、そのまま格納/出力/表示していると考えられる。その結果が図6~7の「□」だったわけだ。これこそがUTS#37のいう「無視」ではあるが……。 UTS#37の立場からは、異体字シーケンスによってサーバーやブラウザが誤動作したわけではないから、図6~7の例は立派に「無視」されたものとなるのかもしれない。しかしユーザーの立場からはどうだろう。異体字シーケンスに対応しない環境では、これらの例のように見慣れない「□」や「・」が混入することになるだろう。一般の人々が、こうした見なれない表示をどのように受け止めるだろうか。 キーになるのは、アプリケーションよりむしろOSでどのように実装されるかだろう。ここで私が心配しているのは、具体的にはMac OS XのテキストエディットやWindows Vistaのメモ帳などで、ユーザーがそれと意識することなく異体字シーケンスが入力されてしまうような実装を指す。慎重な両社のエンジニアがそのような実装を選ぶ可能性はあまりないとは思うが、そうして作られたテキストデータが、そのままブログなどで書き込まれれば、上図のような画面になってしまう。これから実装するメーカーには、熟慮の上で進めていただきたいと思う。 ● 異体字シーケンスは、互換漢字の完全な代替にならない 最後に異体字シーケンスについてまとめてみよう。この技術そのものは、これまで包摂の範囲で意図せず字体が変わっていた「混乱」に対する有効な回答の1つだと思う。現在の我々の国のように、漢字の一点の有無にこだわるような社会では良い解決法になるのではないか。これに対応した環境である限りフォントを切り替えても字体が変わることはない。また対応した環境同士ならば、字体の違いを保持したままプレーンテキストでの情報交換が可能だ。しかしこれも万能ではないことは覚えておきたい。まず互換漢字と同様に、国際化ドメイン名などStringprepが介在するような用途には使えない。そして対応しない環境では「□」等で表示されるから、これを入力する際はユーザーにそれと意識させるべきだし、非対応環境との情報交換ではどのようなことが起きるか周知徹底が必要だろう。その意味では異体字シーケンスは互換漢字が持つ問題点を軽減はしても根絶するものではない。 ここまで第2部として常用漢字表に略字体が追加された場合に起こる「漢字政策の玉突き現象」、そしてインターネットとUnicode正規化の普及によって互換漢字による異体字の符号化が限界に来ている現実、そうした事態に対する技術的な解決策である異体字シーケンスの概要とその問題点について述べた。次回は結論として、常用漢字表の改訂に再び戻ろう。ここまで見てきたさまざまな現実が何を意味するのか、何が本当の問題なのか、そして今後の国語施策はどうあるべきかを考えてみようと思う。 今、私が気になっているのは、紛らわしい文字を排除するというStringprepの目的からは、異体字シーケンスで使われる字形選択子が本来削除されるべき文字であるという事実だ。インターネットにおいては、包摂字体を区別したいという要求そのものもがセキュリティ問題を発生させてしまう。これは何を意味するのか。インターネットの発展とともに、どうやら文字そのものが持つ目的や性質が、正反対の2つに分裂しつつあるように見える。1つはドメイン名だとかID、URIなど公共性の高い文字、もう1つは私的な表現の道具としての文字。互換漢字に未来がないのは確かとして、異体字シーケンスは後者のための技術なのだろうし、そこにこの技術の豊かな未来があるのではないか。そうした意味で字形選択子がStringprepで削除されるのは、むしろ当然なのだ。 そこで問題になるのは、常用漢字はこの2つのうちどちらに入るべきなのかということだ。しかしこの続きは次回ゆっくり考えることにしよう。どうかお楽しみに。
2008/09/10 11:28
- ページの先頭へ-
|