|
記事検索 |
バックナンバー |
【 2009/04/09 】 |
||
| ||
【 2008/11/28 】 |
||
| ||
【 2008/11/27 】 |
||
| ||
【 2008/11/14 】 |
||
| ||
【 2008/11/13 】 |
||
| ||
【 2008/11/12 】 |
||
| ||
【 2008/11/11 】 |
||
| ||
【 2008/10/31 】 |
||
| ||
【 2008/10/30 】 |
||
| ||
【 2008/10/29 】 |
||
| ||
【 2008/10/28 】 |
||
| ||
【 2008/10/27 】 |
||
|
|
|
|||||||||||||||||||||||||||||
| “情報化時代”に追いつけるか? 審議が進む「新常用漢字表(仮)」 |
|||||||||||||||||||||||||||||
|
第2部 新常用漢字表と文字コード規格 |
|||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||
|
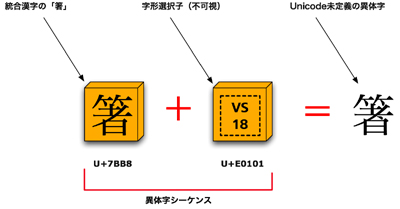
● 字形選択子を使って異体字に置き換える 今回はUTS#37に基づいて、どのように異体字シーケンスが規定されているのか詳しく見てみよう。これの符号表現の考え方は、第2部第5回で述べた結合文字を使った合成列と全く同じものだ(第5回図2/第8回図1参照)。合成列では、例えば「ダ」という平仮名は「タ」(U+30BF)に結合文字の濁点(U+3099)を合成させることで「ダ」という文字の形を表現していた。これと同じように、例えば「箸」を表すU+7BB8の後に特定の文字(これを字形選択子と呼ぶ[*1])を並べることで任意の異体字に置き換える。つまり単一の文字で異体字を表すのでなく、符号を並べて表現するので「シーケンス」(並び)と呼ぶわけだ。
字形選択子は普段は目に見えない特殊な文字とされており、例えば現在のところWindows VistaやMac OS Xでは一般的な手段では入力できない。また、これと合成できるのは統合漢字と拡張領域に収録された漢字だけとされている。つまり互換漢字は異体字シーケンスから排除されている。 ここで注意したいのは、異体字シーケンス用の字形選択子がUnicodeでは第14面のU+E0100からU+E01EFの範囲(240字)に収録されていることだ[*2]。つまりこれを扱うにはサロゲートペアへの対応が前提となる[*3]。もっともWindows VistaやMac OS Xで対応ずみのJIS X 0213の中には第2面に収録された文字があり、これに対応したアプリケーションなら問題なく扱うことができるはずだ。 ● メーカー外字をUnicodeに取り込む枠組み では、異体字シーケンスはどのようにしてUnicodeへの収録が決まるのだろう。これは収録を希望する団体がUnicode社に対して自分たちの文字セットを登録申請する形になっている[*4]。一定の要件と手続きを踏めば誰が登録してもよいし、手続きが適正ならUnicodeは申請を拒む理由はない。一連の流れはUTS#37によって次のように決められている[*5]。
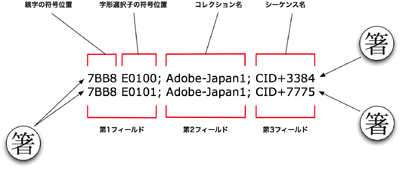
この手順を通してわかることは、要するにこれは今までメーカーが社内で抱え込んでいた外字セットを、第三者のチェックを経由させた後にUnicodeに取り込む手続きであるということだ。そうすることで今までUnicodeで未定義だった文字を情報交換可能にし、メーカー外字セットとの間で往復の保全性を確立できる。 ● 字形選択子は「デフォルト無視可能」 もう1つ大事なことがある。字形選択子はUnicode規格本文によって、これに対応しないOSやアプリケーションにとって不可視であり、同時に無視されなければならないとされる[*8]。つまり同じく不可視である制御符号のように、読み込むと思わぬ動作を引き起こすようなことがあってはならない。だから未対応のOSやアプリケーションで異体字シーケンスを読み込んでも、字形選択子だけ無視されて、その前にある統合漢字が表示されるだけとなる。これをUTS#37では「default ignorable」(デフォルト無視可能)と表現する。前回述べたように、互換漢字はネットワークを伝送していく中で、いつ、どこでUnicode正規化が行われ、統合漢字に置き換わるかわからない不安定な文字だ。この異体字シーケンスも、同様に対応しない環境では統合漢字が表示されることになるから、互換漢字と同じ不安定なもののように思える。しかしそれと違う点は、互換漢字がどこで置き換わるか全く予想できないのに対し、異体字シーケンスでは、対応した環境では指定された異体字、未対応の環境では統合漢字および「□」「・」などの表示と、環境によって振る舞いがあらかじめ想定できる点だ。 また第2部第7回で紹介したMac OS X版InDesign CS3の例のように、互換漢字がUnicode正規化で統合漢字に置き換わった後、変更後の符号位置が確定してしまう場合もあるのに対し[*9]、異体字シーケンスではそういうことはない。未対応環境で統合漢字及び「□」「・」などが表示された場合でも、同じテキストを対応した環境に持ってくれば何事もなかったように異体字を表示する。少なくともUnicode規格本文ではそのような振る舞いを求めている。 ● 包摂された字体が区別可能になる 異体字シーケンスにはここまで述べたメーカーの外字セットを取り込むという目的以外に、常用漢字表の改定など国語施策の動向と関連して、もう1つ大きな目的があると考えられる。実際に今のところ唯一異体字シーケンスのコレクションを登録している、Adobe SystemsのAdobe-Japan1を見てみよう[*10]。UTS#37によれば、異体字シーケンスとしての符号の並びを記録するのは「IVD_Sequences.txt」というテキストファイルということになっている。UnicodeのWebサイトに掲載されているAdobe-Japan1のIVD_Sequences.txtで、ここまで例に挙げてきた「箸」を表すU+7BB8の異体字シーケンスがどうなっているかを抜き出してみよう(図2)。
これを見ると、従来のフォントで符号位置に対応させていた文字の形も含め、Adobe-Japan1で表現可能なすべての異体字が定義されていることがわかる。一見すると、これは無駄なように思える。例えば同社のOpenTypeフォント「小塚明朝Pr6N」は異体字シーケンス対応以前からU+7BB8に対してCID+7775を対応させている。つまり何もしなくてもU+7BB8に対してはCID+7775を表示するようになっていた。それを異体字シーケンスに対応後は、これに加えて異体字シーケンスを使った場合でもCID+7775が出るようにしている。 一見すると無駄なように思えるが、しかしこうすることで今までU+7BB8という符号位置に包摂され、どちらか片方しか使えなかった「CID+3384」と「CID+7775」という文字の形を、区別して使うことが可能になり、フォントを切り替えても「U+7BB8/U+E0101」というシーケンスである限り必ずCID+7775を表示するようになる。 ● フォントを切り替えると字体が変わってしまう「混乱」 ところで、この図2をWindows Vistaで見たユーザーから次のような疑問が出るかもしれない。「自分の環境ではU+7BB8は“点なし”ではなく“点つき”の箸だ」と(これは図1も同様)。そう、現在の日本のコンピュータにおける日本語環境は過渡期にある。U+7BB8に対してデフォルトで「点なしの箸」を対応させる旧来の環境と、同じく「点付きの箸」を対応させる新しい環境が併存している状態だ。上の図2は「旧来の環境」(フォント)によって作成されたものだから、例えばWindows Vistaなどでこれを見た人は、「自分のパソコンの字と違う」と違和感を持つことになる。これは具体的にいうと、「旧来の環境」が2000年に制定されたJIS X 0213初版に基づくのに対し、「新しい環境」は2004年改正版に基づくことによる。第2部第1回で少し説明したように、2004年の改正では表外漢字字体表(2000年国語審議会答申)に対応するため、168面区点の例示字体変更を行った(図3)。そこで例えばWindows XPやバージョン10.4までのMac OS XはJIS X 0213初版、対してWindows VistaやMac OS Xバージョン10.5では2004年改正版に基づくフォントをデフォルトとするというような違いが生じた。
つまりOSが標準装備するフォントのマッピングによって、字体が異なる漢字が表示されてしまう。これは文字コード規格の改正により発生した事態なのだが、だからといって責任を文字コード規格に負わすことはできない。文字コード規格では符号位置に対応付けられる文字に対して一定の範囲で字体の揺れを許している。これが包摂の範囲だ(UCS/Unicodeでは統合の範囲)。そのような揺れがあっても「同じ字とされる社会的な合意」があり、混乱は発生しないと信じられたからだ。この「箸」の場合でいえば、点の有無が問題にされること自体が文字コード規格の想定外だったことになる。包摂の範囲内で字体が変わることは、規格にとってある意味当然なのだ。しかし国語施策としての表外漢字字体表はこれを問題にし、点のある「箸」の方を正統とした。この「混乱」はここに起因する[*12]。 異体字シーケンスはこれを解決しようとする目的があると思われる。続きは次回で説明しよう。また次回は第2部の最後として、この異体字シーケンスが本当に互換漢字の代わりとなりうるのかを考えてみたい。
● 修正履歴 [訂正]……原稿の以下の部分で、「Unicode」のスペルを書き間違えていました。お詫びして訂正いたします。 誤:[*4]……Unicdeコンソーシアムは1991年にカルフォルニア州にUnicide Inc.として法人設立している。ここでは「Unicide社」と表記する。 ご指摘いただいた芝野耕司氏に感謝いたします。(2008/9/12) 2008/09/09 12:24
- ページの先頭へ-
|