|
記事検索 |
最新ニュース |
|
|
||||||||||||||||
|
現代日本語の研究などに「Yahoo!ブログ」の記事を収集・提供へ |
||||||||||||||||
|
|
||||||||||||||||
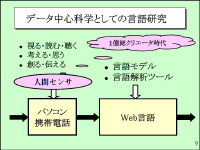
すでにヤフーでは、研究用のデータとして「Yahoo!知恵袋」のデータを提供している。CGMデータの研究利用の第一歩ということで画期的な試みだったが、サイトの性質上、Q&Aという一定の型に従った投稿が多いため、研究者からは表現の自由度の高いブログのデータの収集が望まれていたという。 提供するブログデータは、インターネット全体に公開されているブログを対象に、4月25日以降に投稿された記事から最低500万語のサンプルを収集。季節ごとに数回サンプルを抽出する。なお、個人の特定に結び付く可能性のある固有名詞などの表現は除外するとしており、そのためのガイドラインを策定中だ。 また、ヤフーによれば、提供するのはブログの記事本文に限定するという。ブログ開設者からの許諾については、Yahoo! JAPAN IDを取得した際に利用規約に同意した段階でクリアしているため、問題ないと説明した。一方、Yahoo! JAPAN IDがなくても書けるコメント部分については、今回は提供しないとした。 NII副所長の東倉洋一氏によると、ブログの言語は「書き言葉」と「話し言葉」の両方の性質を持つ、ちょうど中間の言語ととらえることができる。そのため、文の区切りが不明確であるとともに、顔文字などの文字列が混入していたり、くだけた文体による形態素解析や構文解釈の誤りが起こり、新しい言語モデルや言語解析ツールが必要になっているという。 ヤフーから体系的なブログデータの提供を受けることで、CGMを対象とした情報検索や情報分析、情報活用などの研究に役立てる。データの提供はNIIを通じて7月から開始する予定で、大学などの研究機関のほか、民間企業などにも提供する。
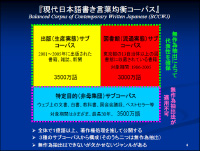
現代日本語書き言葉均衡コーパスは1億語以上を収集して著作権処理をした上で公開する計画。書籍や雑誌、新聞を対象とした「出版(生産実態)サブコーパス」(3,500万語)、図書館の蔵書を対象とした「図書館(流通実態)サブコーパス」(3,000万語)、教科書や国会の会議録などを対象とした「特定目的(非母集団)サブコーパス」の3種類で構成される。 国語研の言語資源グループ長である前川喜久雄氏によると、無作為抽出の出版サブコーパスと図書館サブコーパスではカバーしきれない言葉があり、「サンプルの多様性をとらえる上で、ネット上の情報が重要」。これらWeb上の文書を特定目的サブコーパスに収録することにした。すでにYahoo!知恵袋からも500万語のテキストデータが作成されているという。 コーパスは2011年度に公開予定で、インターネット上では検索の機能や表示件数を限定したものを無償公開する。一方、研究者向けには、全データを有償提供する。 関連情報 ■URL ニュースリリース http://www.nii.ac.jp/news_jp/2008/04/_yahoo_1.shtml ■関連記事 ・ 「Yahoo!知恵袋」のデータを研究目的で利用、国立情報学研究所が契約締結(2007/03/06) ・ ヤフー、検索語データを情報爆発プロジェクトの研究者向けに無償提供(2008/03/03)
( 永沢 茂 )
- ページの先頭へ-
|